Chapter9 Regression
In this chapter we are going to see how to conduct a regression analysis with time series data.
Regression analysis is a used for estimating the relationships between a dependent variable (DV) (also called outcome or response) and one or more independent variables (IV) (also called predictors or explanatory variables).
A standard regression model \(Y\) = \(\beta\) + \(\beta x\) + \(\epsilon\) has no time component. Differently, a time series regression model includes a time dimension and can be written, in a simple and general formulation, using just one explanatory variable, as follows:
\[ y_t = \beta_0 + \beta_1x_t + \epsilon_t \]
In this equation, \(y_t\) is the time series we try to understand/predict (the dependent variable (DV)), \(\beta_0\) is the intercept (a constant value that represents the expected mean value of \(y_t\) when \(x_t = 0\)), the coefficient \(\beta_1\) is the slope, representing the average change in \(y\) at one unit increase in \(x\) (the independent variable (IV) or explanatory variable), and \(\epsilon_t\) is the time series of residuals (the error term).
A multiple regression, with more than one explanatory variable, can be written as follows:
\[ y_t = \beta_0 + \beta_1x_{1,t} + \beta_2x_{2,t} + ... + \beta_kx_{k,t} + \epsilon_t \]
9.1 Static and Dynamic Models
From a time series analysis perspective, a general distinction can be made between “static” and “dynamic” regression models:
- A static regression model includes just contemporary relations between the explanatory variables (independent variables) and the response (dependent variable). This model could be appropriate when the expected value of the response changes immediately when the value of the explanatory variable changes. Considering a model with \(k\) independent variables {\(x_1\), \(x_2\), …, \(x_k\)}, a static (multiple) regression model, has the form just seen above:
\[ y_t = \beta_0 + \beta_1x_{1,t} + \beta_2x_{2,t} + ... + \beta_kx_{k,t} + \epsilon_t \]
Each \(\beta\) coefficient models the instant change in the conditional expected value of the response variable \(y_t\) as the value of \(x_{k,t}\) changes by one unit, keeping constant all the other predictors (i.e.: the other \(x_{k,t}\)):
- A dynamic regression model includes relations between both the current and the lagged (past) values of the explanatory (independent) variables, that is, the expected value of the response variable may change after a change in the values of the explanatory variables.
\[ \begin{split} y_t &= \beta_0 + \beta_{10} x_{1,t} + \beta_{11} x_{1,t-1} + \dots + \beta_{1m} x_{1,t-m} \\ &\quad + \beta_{20} x_{2,t} + \beta_{21} x_{2,t-1} + \dots + \beta_{2m} x_{2,t-m} \\ &\quad + \dots \\ &\quad + \beta_{k0} x_{k,t} + \beta_{k1} x_{k,t-1} + \dots + \beta_{km} x_{k,t-m} \\ &\quad + \epsilon_t \end{split} \]
Despite the differences between these two analytic perspectives, the term dynamic regression is also used, in the literature, in a more general way to refer to regression models with autocorrelated errors (also when they are used to analyze only contemporary relations between variables).
9.2 Regression models
Except for the possible use of lagged regressors, which are typical of time series, the above described statistical models are standard regression models, commonly used with cross-sectional data.
Standard linear regression models can sometimes work well enough with time series data, if specific conditions are met. Besides standard assumptions of linear regression1, a careful analysis should be done in order to ascertain that residuals are not autocorrelated, since this can cause problems in the estimated model.
In this chapter we’ll see how to deal with autocorrelated residuals. However, even before that, it is important that the series are stationary, in order to avoid possible spurious correlations.
9.2.1 Stationarity
We already discussed stationarity in the previous chapters. Here we can observe that time series can be nonstationary due to different reasons, thus different strategies can be employed to stationarize the data.
For instance, a nonstationary series can be a series with unequal variance over time. A common way to try to fix the problem is by applying a log-transformation.
library(xts)
elections_news <- read.csv("data/elections-stories-over-time-20210111144254.csv")
elections_news$date <- as.Date(elections_news$date)
elections_news <- xts(elections_news$count, order.by = elections_news$date)
elections_news_log <- log(elections_news+1)
elections_news_xts <- merge.xts(elections_news, elections_news_log)
plot.xts(elections_news_xts, col = c("blue", "red"),
multi.panel = TRUE, yaxis.same = FALSE,
main = "Original vs Log-transformed series")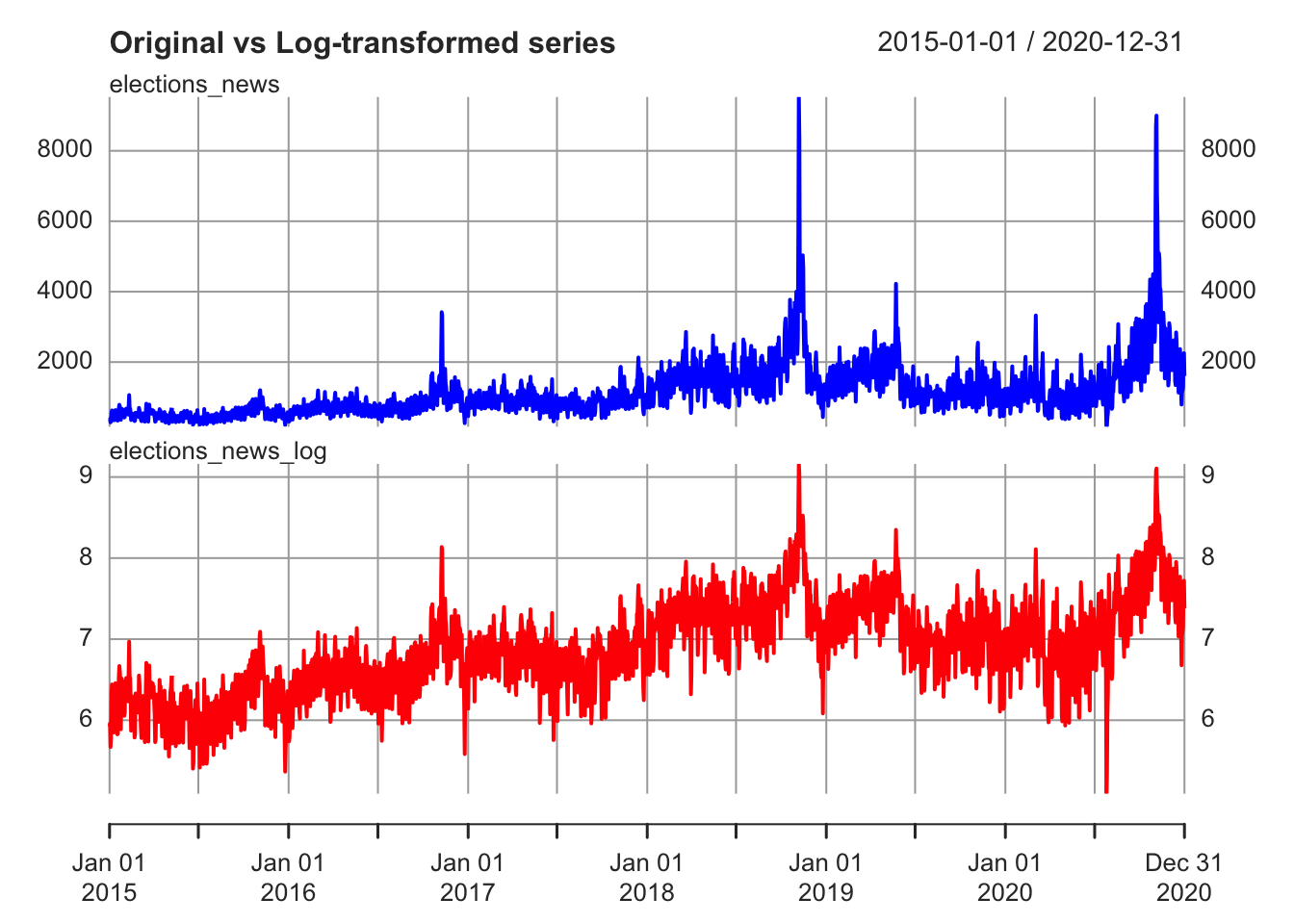
Another reason for nonstationarity is the periodic variation due to seasonality (regular fluctuations in a time series that follow a specific time pattern, e.g.: social media activity during week-ends, Christmas effect in consumption, etc.).
To remove the seasonal pattern, you might want to use a seasonally-adjusted time series. Otherwise, you could create a dummy variable for the seasonal period (that is, a variable that follows the seasonal pattern in the data in order to account, in the model, for these fluctuations).
# load the ts dataset AirPassenger
data("AirPassengers")
# remove seasonality from a multiplicative model
AirPassengers_decomposed <- decompose(AirPassengers, type="multiplicative")
AirPassengers_seasonal_component <- AirPassengers_decomposed$seasonal
AirPassengers_seasonally_adjusted <- AirPassengers/AirPassengers_seasonal_component
par(mfrow=c(1,2))
plot.ts(AirPassengers, col = "blue", main = "Original series")
plot.ts(AirPassengers_seasonally_adjusted, col = "blue",
main = "Seasonally-adjusted series",
ylab = "Seasonally-adjusted values")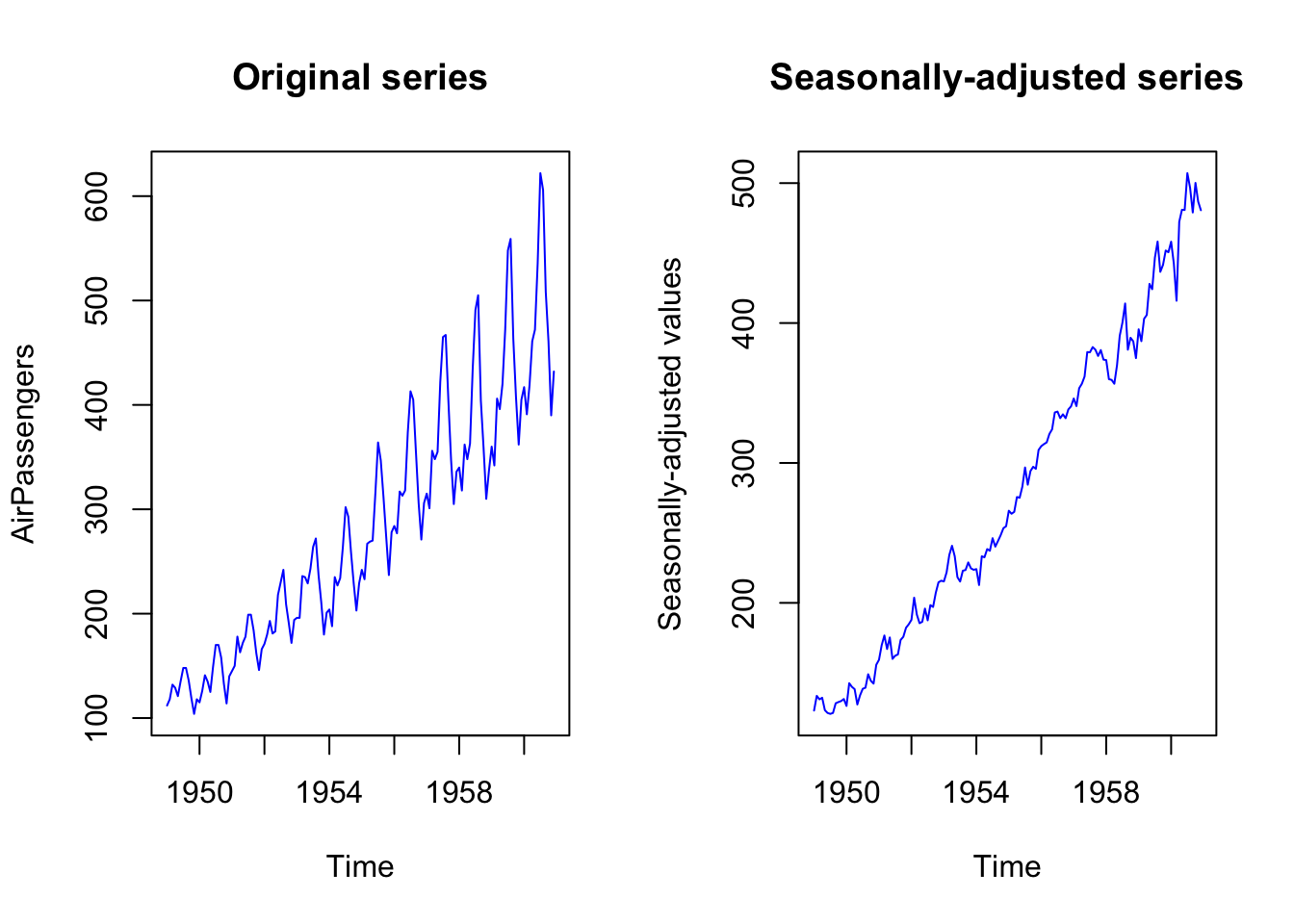
An important reason for nonstationarity is also the presence of a trend in the data. There are stochastic trends and deterministic trends. Deterministic trends are a fixed function of time, while stochastic trends change in an unpredictable way.
Series with a deterministic trend are also called trend stationary because they can be stationary around a deterministic trend, and it could be possible to achieve stationarity by removing the time trend. In trend stationary processes, the shocks to the process are transitory and the process is mean reverting.
Processes with a stochastic trend are also called difference stationary because they can become stationary through differencing. In series with stochastic trends we could see that shocks have permanent effects.
When dealing with deterministic trend, we might want to work with detrended series.
# remove the trend from a multiplicative model
AirPassengers_decomposed <- decompose(AirPassengers, type="multiplicative")
AirPassengers_trend_component <- AirPassengers_decomposed$trend
AirPassengers_detrended <- AirPassengers/AirPassengers_trend_component
par(mfrow=c(1,2))
plot.ts(AirPassengers, col = "blue", main = "Original series")
plot.ts(AirPassengers_detrended, col = "blue",
main = "Detrended series",
ylab = "Detrended values")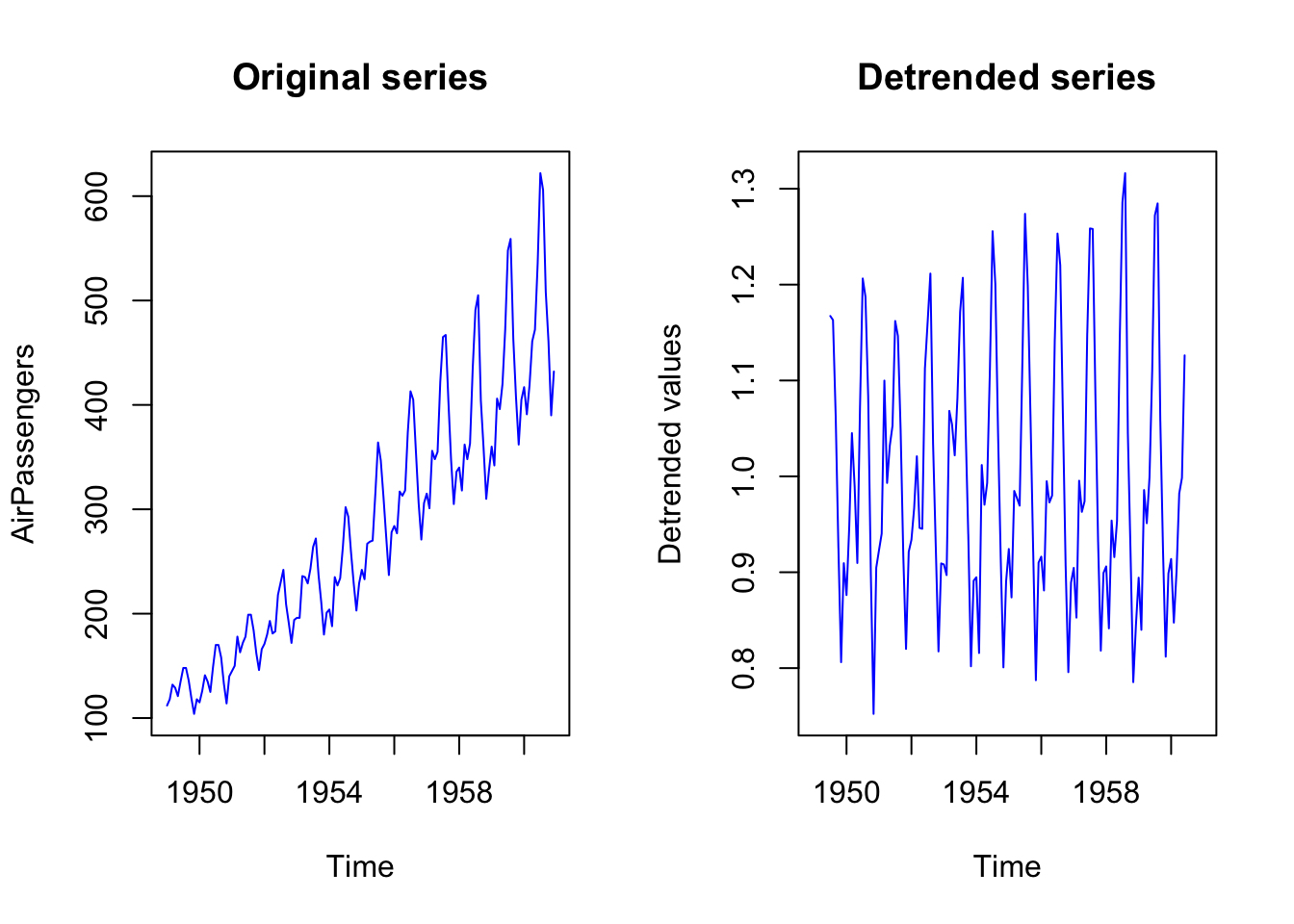
Otherwise, in regression analysis, it is more common to add a dummy variable consisting of a value that increases with time, to account for a linear deterministic time trend. This time-count variable will remove the deterministic trend from the dependent variable, allowing the other predictors to explain the remaining variance.
# create a simulate series
set.seed(1312)
toy_data <- arima.sim(n = 100, model = list(order = c(0,0,0)))
# add a deterministic trend to the series
toy_data_trend <- toy_data + 0.2*1:length(toy_data)
par(mfrow=c(1,3))
plot.ts(toy_data, main = "Original series")
plot.ts(toy_data_trend, main = "Series with Trend")
dummy_trend <- 1:length(toy_data_trend)
lm_toydata <- lm(toy_data_trend ~ dummy_trend)
plot.ts(lm_toydata$residuals, main = "Residuals (detrended)")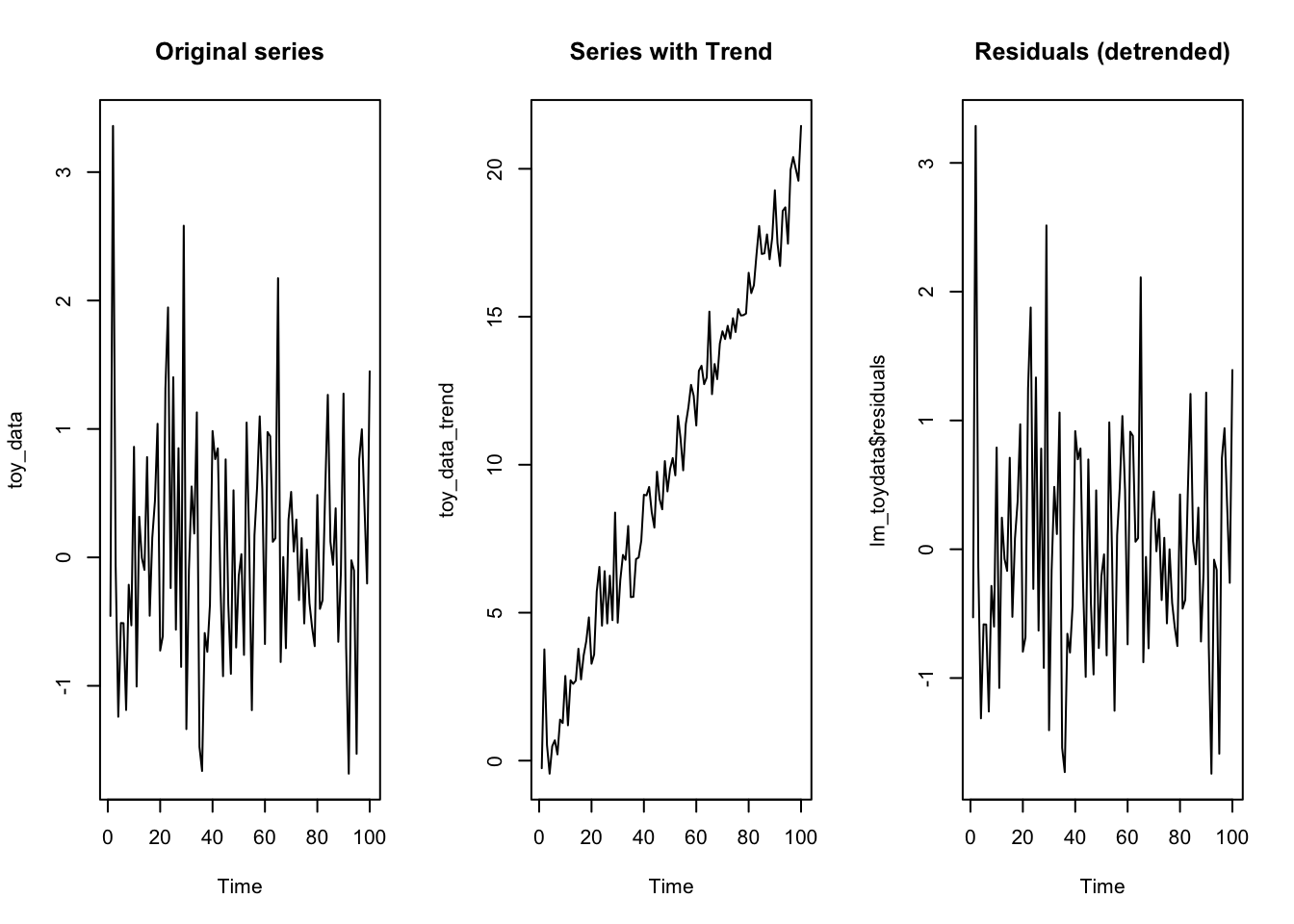
When we have a series with a stochastic trend, we can achieve stationarity through differencing.
set.seed(111)
Random_Walk <- arima.sim(n = 500, model = list(order = c(0,1,0)))
Random_Walk_diff <- diff(Random_Walk)
par(mfrow=c(1,2))
plot.ts(Random_Walk,
main = "Random Walk",
col = "blue", ylab="")
plot.ts(Random_Walk_diff,
main = "Differenced Random Walk",
col = "blue", ylab="")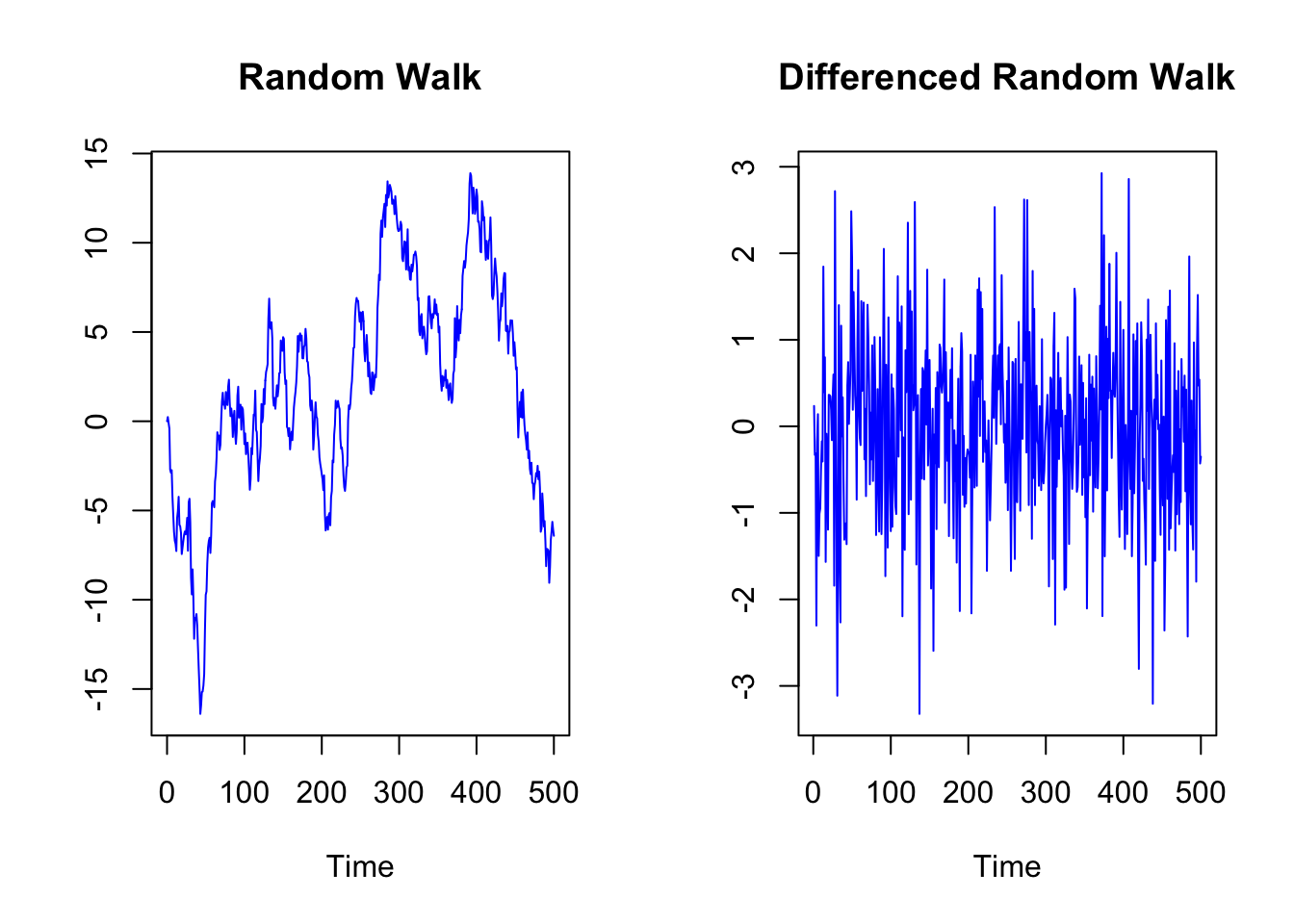
9.2.1.1 Tests for Stochastic and Deterministic Trend
The correct detrending method depends on the type of trend. First differencing is appropriate for intergrated I(1) time series and time-trend regression is appropriate for trend stationary I(0) time series.
In case of deterministic trend, differencing is the incorrect solution, while detrending the series in function of time (regressing the series on a variable such as time and saving the residuals) is the correct solution. Differencing when none is required (over-differencing) may induce dynamics into the series that are not part of the data-generating process (for instance, it could create a first-order moving average process).
Specific statistical tests have been developed to distinguish between the two types of trends. In particular, unit root tests and stationary test can be used to determine if trending data should be first differenced or regressed on deterministic functions of time to render the data stationary.
Considering a simple model like the following, where \(Td\) is a deterministic linear trend and \(z_t\) is an autoregressive process of order 1 AR(1). The difference between a process with stochastic and deterministic trend can be traced back to the parameter \(|\phi|\): When \(|\phi| = 1\), then \(z_t\) is a stochastic trend and \(y_t\) is an integrated process I(1) with drift (the so-called “drift” refers to the presence of a constant term, in this case \(\kappa\)). When \(\phi < 1\), the process is not integrated (I(0)) and \(y_t\) exhibits a deterministic trend2:
\[ \begin{split} y_t &= Td_t + z_t \\ Td_t &= \kappa + \delta_t \\ z_t &= \phi z_{t-1} + \epsilon_t, \quad \epsilon_t \sim N(0, \sigma^2) \end{split} \]
Let’s simulate and visualize the above equation (\(y_t = \kappa + \delta_t + \phi z_{t-1} + \epsilon_t\)):
set.seed(123)
t <- 1:500
kappa <- 5 # costant term (or "drift")
delta <- 0.1
epsilon <- function(n){ # function for the error term
rnorm(n = 500, mean = 0, sd = 0.8)
}
y_I1 <- kappa + (delta * t) + arima.sim(n=499, list(order = c(0,1,0)),
rand.gen = epsilon)
y_I0 <- kappa + (delta * t) + arima.sim(n=500, list(order = c(1,0,0), ar = 0.8),
rand.gen = epsilon)
ts_y <- ts.intersect(y_I1, y_I0)
plot.ts(ts_y, plot.type = "single",
lty=c(1,3), col=c("red", "blue"),
main = "Stochastic w/ drift (red) Deterministic Trend (blue)",
ylab="")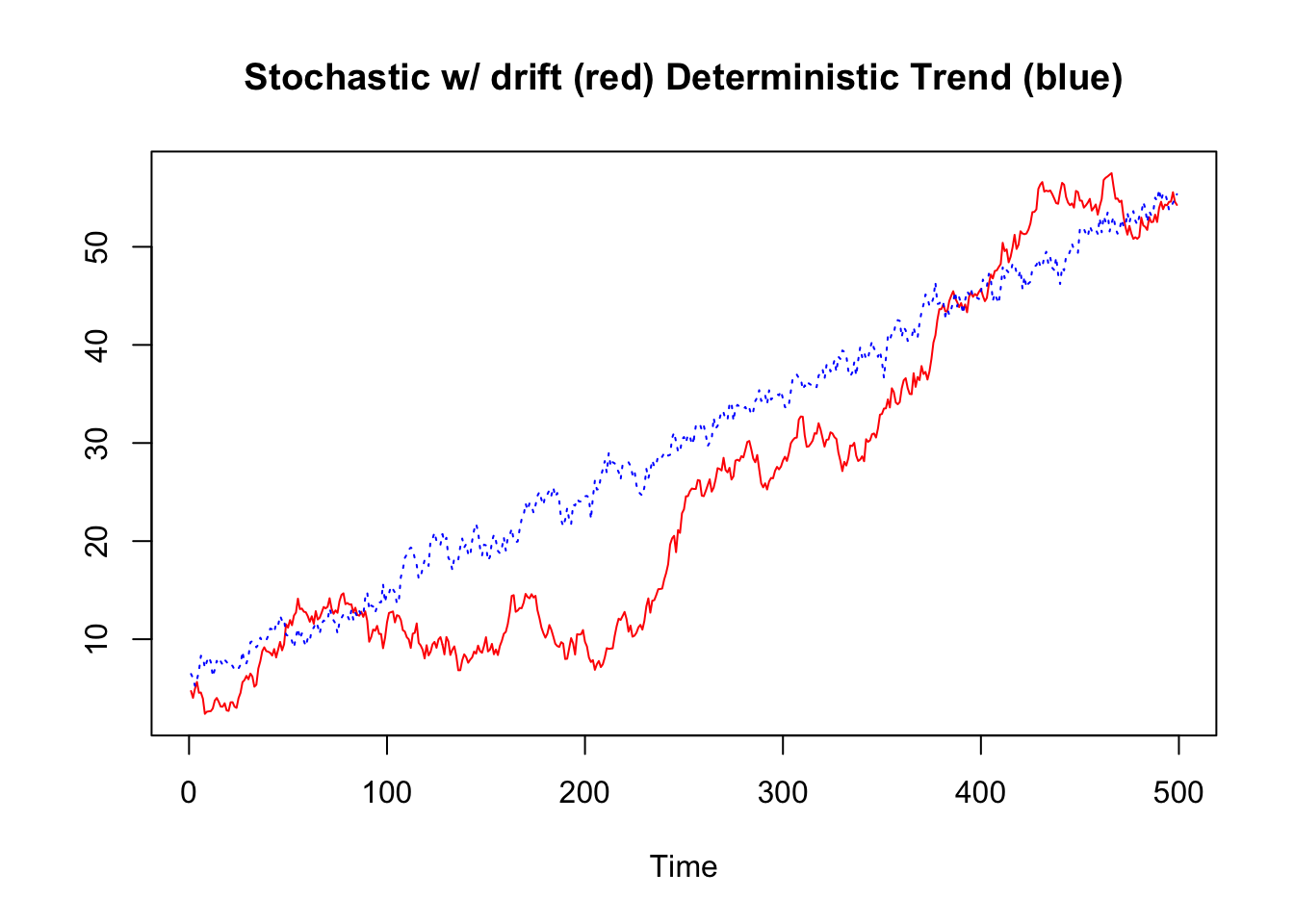
Unit root tests are aimed at testing the null hypothesis that \(|\phi| = 1\) (difference stationary), against the alternative hypothesis that \(|\phi| < 1\) (trend stationary).
Stationarity tests take the null hypothesis that \(y_t\) is trend stationary, and are based on testing for a moving average element in \(\Delta z_t\) (\(\Delta\) represents the operation of differencing).
\[ \begin{split} \text{Original} \\ y_t &= Td_t + z_t \\ Td_t &= \kappa + \delta_t \\ z_t &= \phi z_{t-1} + \epsilon_t, \quad \epsilon_t \sim N(0, \sigma^2) \end{split} \]
\[ \begin{split} \text{First difference} \\ \Delta y_t &= \Delta Td_t + \Delta z_t \\ \Delta Td_t &= \Delta \kappa + \Delta \delta_t = \delta \\ \Delta z_t &= \phi \Delta z_{t-1} + \Delta \epsilon_t = \phi \Delta z_{t-1} + \epsilon_t - \epsilon_{t-1} \end{split} \]
\(\Delta z_t\) can be also written as:
\[ \Delta \epsilon_t = \phi \Delta z_{t-1} + \epsilon_t + \theta \epsilon_{t-1} \]
with \(\theta = -1\). That is, when the series is trend stationary, taking the first difference results in overdifferencing and in the creation of a moving average (MA) term \(\theta \epsilon_{t-1}\). The creation of a moving average element, which is missing in the original series, is also why differencing a trend-stationary process is problematic.
9.2.1.1.1 KPSS Test
A test to verify if the series is trend stationary is the Kwiatkowski-Phillips-Schmidt-Shin (KPSS) test. It is one of the most commonly used stationarity test, and is implemented in the library tseries (function kpss.test). KPSS test the null hypothesis that the series is trend stationary.
In this case, the p-value of the test is higher than 0.05, so the test cannot reject the null hypothesis of trend stationarity. That is to say, there are some evidence of trend-stationary process.
# install.packages("tseries") # install the library if not yet installed
library(tseries)
kpss.test(y_I0, null = "Trend")##
## KPSS Test for Trend Stationarity
##
## data: y_I0
## KPSS Trend = 0.10404, Truncation lag parameter = 5, p-value = 0.1By changing the null from “Trend” to “Level”, the KPSS test can also test the null hypothesis of level stationarity. A level stationary time series is a time series with a non-zero but constant mean, that is to say, without trend.
kpss.test(y_I0, null = "Level")##
## KPSS Test for Level Stationarity
##
## data: y_I0
## KPSS Level = 8.4092, Truncation lag parameter = 5, p-value = 0.01In this case, the KPSS test for level stationarity reject the null hypothesis, that is to say, the process seems not to be level stationary. Considered together, the KPSS tests suggest that the series has a deterministic trend.
If we use the KPSS test to test if the stochastic trend series we created above is trend or level stationary, the test rejects the null hypothesis (i.e.: reject the hypothesis of both a trend and level stationary process).
kpss.test(y_I1, null = "Trend")##
## KPSS Test for Trend Stationarity
##
## data: y_I1
## KPSS Trend = 1.5, Truncation lag parameter = 5, p-value = 0.01
kpss.test(y_I1, null = "Level")##
## KPSS Test for Level Stationarity
##
## data: y_I1
## KPSS Level = 7.7377, Truncation lag parameter = 5, p-value = 0.01When a series has a stochastic trend, we can achieve stationarity through differencing. Indeed, the KPSS test does not reject the null hypothesis of level stationarity when applied to the the stochastic-trend series, once differenced.
##
## KPSS Test for Level Stationarity
##
## data: diff(y_I1)
## KPSS Level = 0.18432, Truncation lag parameter = 5, p-value = 0.1In the above cases the KPSS results are correct, since we have simulated and tested a time series with a deterministic and stochastic trend. However, these kind of tests can also be wrong. For instance, it is possible they reject the null hypothesis when it is actually true (“Type I error”). For this reason, it can be useful to use more than one test. For instance, the KPSS can be used along with the Augmented Dickey-Fuller Test (ADF), a popular unit root test.
9.2.1.1.2 Augmented Dickey-Fuller (ADF) Test
The Augmented Dickey-Fuller Test (ADF) is a popular unit root test. An R implementation of the test can be found in the library tseries (function adf.test). The null hypothesis is that the series has a unit root, and the alternative hypothesis is that the series is stationary or trend stationary.
If we use the ADF test on the integrated series (which has a unit root), the test fails to reject the null hypothesis of unit root, which is correct.
adf.test(y_I1)##
## Augmented Dickey-Fuller Test
##
## data: y_I1
## Dickey-Fuller = -1.7632, Lag order = 7, p-value = 0.6785
## alternative hypothesis: stationaryIf we use the ADF test on the trend-stationary series (without unit root), the test rejects the null hypothesis of unit root, which is correct.
adf.test(y_I0)##
## Augmented Dickey-Fuller Test
##
## data: y_I0
## Dickey-Fuller = -5.8397, Lag order = 7, p-value = 0.01
## alternative hypothesis: stationaryIf we use the ADF test on the integrated series, after having transformed it through differencing, the test rejects the null hypothesis of unit root, which is correct.
##
## Augmented Dickey-Fuller Test
##
## data: diff(y_I1)
## Dickey-Fuller = -7.8913, Lag order = 7, p-value = 0.01
## alternative hypothesis: stationary9.2.1.1.3 Phillips-Perron Test
Another unit root test is the Phillips-Perron test. It differs from the ADF test in some aspects (how it deals with serial correlation and heteroskedasticity in the errors). Also this test is implemented in the library tseries (funtion pp.test). Results of the test are similar to those of the ADF test:
# series with deterministic trend
pp.test(y_I0)##
## Phillips-Perron Unit Root Test
##
## data: y_I0
## Dickey-Fuller Z(alpha) = -144.04, Truncation lag parameter = 5,
## p-value = 0.01
## alternative hypothesis: stationary
# series with unit roots
pp.test(y_I1)##
## Phillips-Perron Unit Root Test
##
## data: y_I1
## Dickey-Fuller Z(alpha) = -5.4817, Truncation lag parameter = 5,
## p-value = 0.8039
## alternative hypothesis: stationary##
## Phillips-Perron Unit Root Test
##
## data: diff(y_I1)
## Dickey-Fuller Z(alpha) = -489.82, Truncation lag parameter = 5,
## p-value = 0.01
## alternative hypothesis: stationaryIn case of uncertainty, more than one test can be used.
9.2.2 Non-autocorrelated residuals
We try to fit a linear regression model. First, we create two series \(x\) and \(y\), with \(x\) correlated with \(y\) at lags \(x_{t-3}\) and \(x_{t-4}\).
# simulated data of x series correlated to y at lag 3 and 4
set.seed(999)
x_series <- arima.sim(n = 200, list(order = c(1,0,0), ar = 0.7, sd=1))
z <- ts.intersect(stats::lag(x_series, -3), stats::lag(x_series, -4))
y_series <- 15 + 0.8*z[,1] + 1.5*z[,2] + rnorm(196,0,1)
xy_series <- ts.intersect(y_series, z)The real model (in this case we know it because we created it through the above simulation), is as follows:
\[ y_t = 15 + 0.8x_{t-3} + 1.5x_{t-4} + \epsilon_t \\ \epsilon \sim N(0, 1) \] #### lm
To fit a linear regression, we can use the function lm (the standard funtion to perform linear regression analysis in base R, no additional packages are necessary).
lm1 <- lm(xy_series[,1] ~ xy_series[,2] + xy_series[,3])The function summary prints the summary of the model, which includes the estimates (the “coefficients” of the variables), the standard errors, the statistical significance of the variables, and other information.
summary(lm1)##
## Call:
## lm(formula = xy_series[, 1] ~ xy_series[, 2] + xy_series[, 3])
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.57051 -0.73392 0.06238 0.74187 2.14794
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 14.96869 0.07238 206.80 <2e-16 ***
## xy_series[, 2] 0.85549 0.07680 11.14 <2e-16 ***
## xy_series[, 3] 1.42126 0.07678 18.51 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.002 on 196 degrees of freedom
## Multiple R-squared: 0.873, Adjusted R-squared: 0.8717
## F-statistic: 673.5 on 2 and 196 DF, p-value: < 2.2e-16We said that regression models sometimes work well enough with time series data, if specific conditions are met. Regards the conditions (or assumptions), in particular, the residuals of the models should have zero mean, they shouldn’t show any significant autocorrelation, and they should be normally distributed.
To check whether these assumptions are met, we can visualize the plot of residuals, its ACF/PACF and histogram, and also test the residuals for possible autocorrelation using a statistical test like the Breusch-Godfrey test (this test is the default in the forecast library when a linear regression object lm is tested).
To create the plots we can use the base R functions, or we can use the convenient checkresiduals function in the forecast package.
In this case everything seems fine.
# install.package("forecast") # install the package if necessary
library(forecast)
checkresiduals(lm1)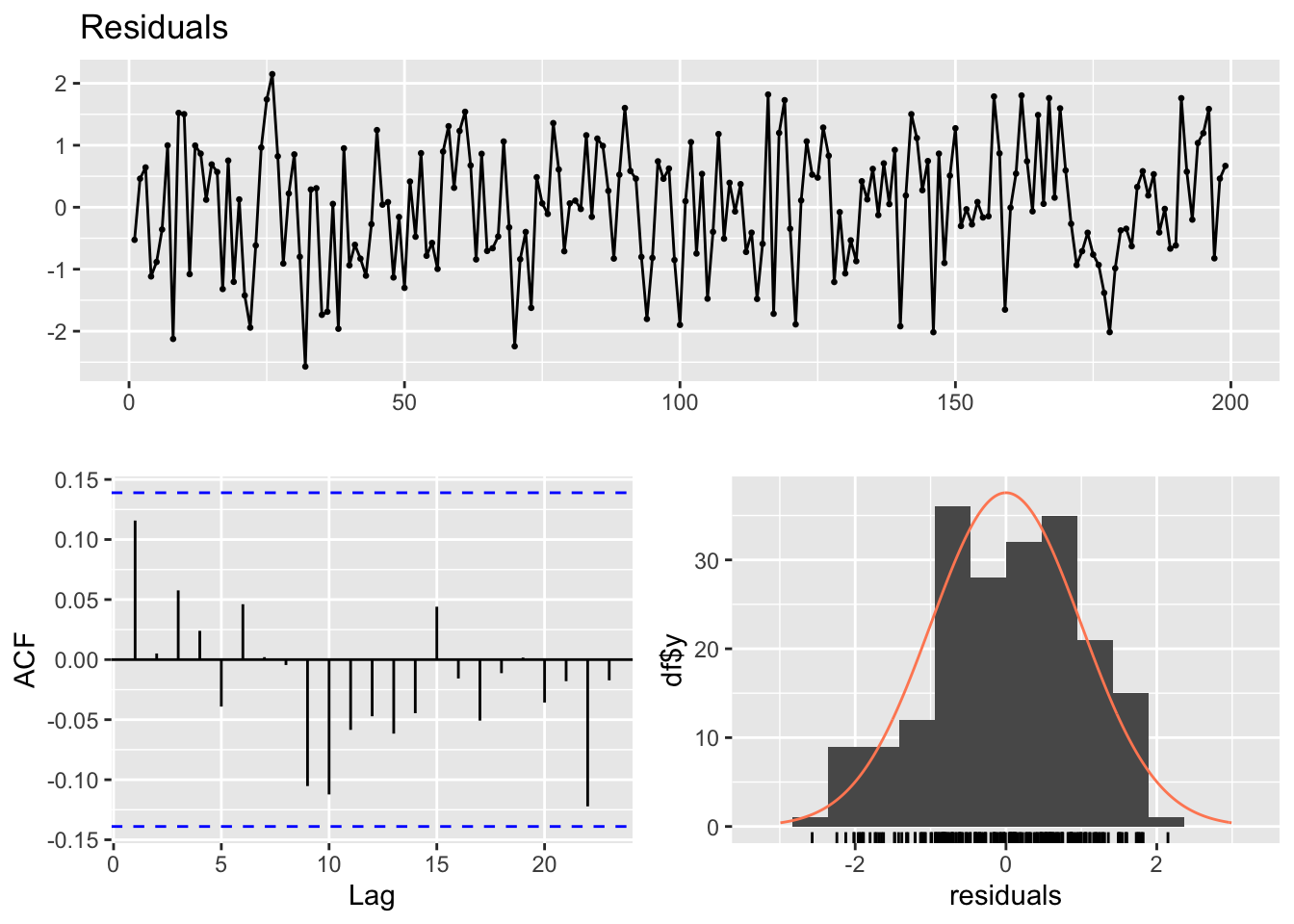
##
## Breusch-Godfrey test for serial correlation of order up to 10
##
## data: Residuals
## LM test = 8.689, df = 10, p-value = 0.5618If we look at the model summary printed above, we can see that the estimated model is the following (the standard deviation of residuals is misnamed as “residual standard error” in the summary of lm):
\[ y_t = 14.96869 + 0.85549x_{t-3} + 1.42126x_{t-4} + \epsilon_t \\ \epsilon \sim N(0, 1.002^2) \] The estimated model is also close to the “true” model:
\[ y_t = 15 + 0.8x_{t-3} + 1.5x_{t-4} + \epsilon_t \\ \epsilon \sim N(0, 1) \] #### dynml
Instead of lm, the package dynml and the function with the same name (dynml) can be used to fit a dynamic regression models in R. One of the main advantages of this package is that it allows users to fit time series linear regression models without calculating the lagged values by hand. To add a lagged variable, it can simply be used the L (Lag) function. The L function takes as arguments the name of the variable and the lag length. For instance L(x, 4) corresponds to \(x_{t-4}\).
# install.packages("dynml") # install the package if necessary
library(dynlm)
dynlm.fit <- dynlm(y_series ~ L(x_series, 3) + L(x_series, 4))
summary(dynlm.fit)##
## Time series regression with "ts" data:
## Start = 5, End = 203
##
## Call:
## dynlm(formula = y_series ~ L(x_series, 3) + L(x_series, 4))
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.57051 -0.73392 0.06238 0.74187 2.14794
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 14.96869 0.07238 206.80 <2e-16 ***
## L(x_series, 3) 0.85549 0.07680 11.14 <2e-16 ***
## L(x_series, 4) 1.42126 0.07678 18.51 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.002 on 196 degrees of freedom
## Multiple R-squared: 0.873, Adjusted R-squared: 0.8717
## F-statistic: 673.5 on 2 and 196 DF, p-value: < 2.2e-16The dynlm function also permits to include trend (function trend) and seasonal (function season) components in the model (it is also possible to change the reference value for the seasonal period, see ?dynlm). Just to make an example of the code to perform a dynamic regression with dynlm:
set.seed(123)
data("AirPassengers")
ap <- log(AirPassengers)
ap_x <- 2 * stats::lag(ap, -3) + rnorm(length(ap), 0, 0.2)
ap_fm <- dynlm(ap ~ trend(ap) + season(ap) + L(ap_x, 3))
summary(ap_fm)##
## Time series regression with "ts" data:
## Start = 1949(7), End = 1960(12)
##
## Call:
## dynlm(formula = ap ~ trend(ap) + season(ap) + L(ap_x, 3))
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.156306 -0.035098 0.007821 0.041535 0.141713
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.116392 0.224848 18.307 < 2e-16 ***
## trend(ap) 0.105758 0.005596 18.899 < 2e-16 ***
## season(ap)Feb -0.026936 0.024867 -1.083 0.280811
## season(ap)Mar 0.127650 0.026209 4.870 3.32e-06 ***
## season(ap)Apr 0.111029 0.028324 3.920 0.000146 ***
## season(ap)May 0.132132 0.031750 4.162 5.86e-05 ***
## season(ap)Jun 0.248250 0.030001 8.275 1.71e-13 ***
## season(ap)Jul 0.334578 0.027595 12.125 < 2e-16 ***
## season(ap)Aug 0.333578 0.029138 11.448 < 2e-16 ***
## season(ap)Sep 0.172679 0.026344 6.555 1.35e-09 ***
## season(ap)Oct 0.034292 0.026311 1.303 0.194866
## season(ap)Nov -0.101556 0.027526 -3.689 0.000335 ***
## season(ap)Dec -0.010445 0.024767 -0.422 0.673966
## L(ap_x, 3) 0.061495 0.022439 2.741 0.007039 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.05831 on 124 degrees of freedom
## Multiple R-squared: 0.9829, Adjusted R-squared: 0.9811
## F-statistic: 546.9 on 13 and 124 DF, p-value: < 2.2e-169.2.3 Regression with ARMA errors
While in the previous case a standard linear model works well, it is often the case that residuals of times series regressions are autocorrelated, and a linear regression model can be suboptimal or even wrong. For instance, let’s create other two time series that are, as the previous ones, cross-correlated at lag 3 and 4, but with a bit more complicated structure.
# another set of simulated data
# the x series is correlated at lag 3 and 4
set.seed(999)
x2_series <- arima.sim(n = 200, list(order = c(1,0,0), ar = 0.7, sd=1))
z2 <- ts.intersect(x2_series, stats::lag(x2_series, -3), stats::lag(x2_series, -4))
y2_series <- 15 + 0.8*z2[,2] + 1.5*z2[,3]
y2_errors <- arima.sim(n = 196, list(order = c(1,0,1), ar = 0.6, ma = 0.6), sd=1)
y2_series <- y2_series + y2_errors
# check the cross-correlations at lag 3 and 4
library(TSA)
prew <- prewhiten(x2_series, y2_series) 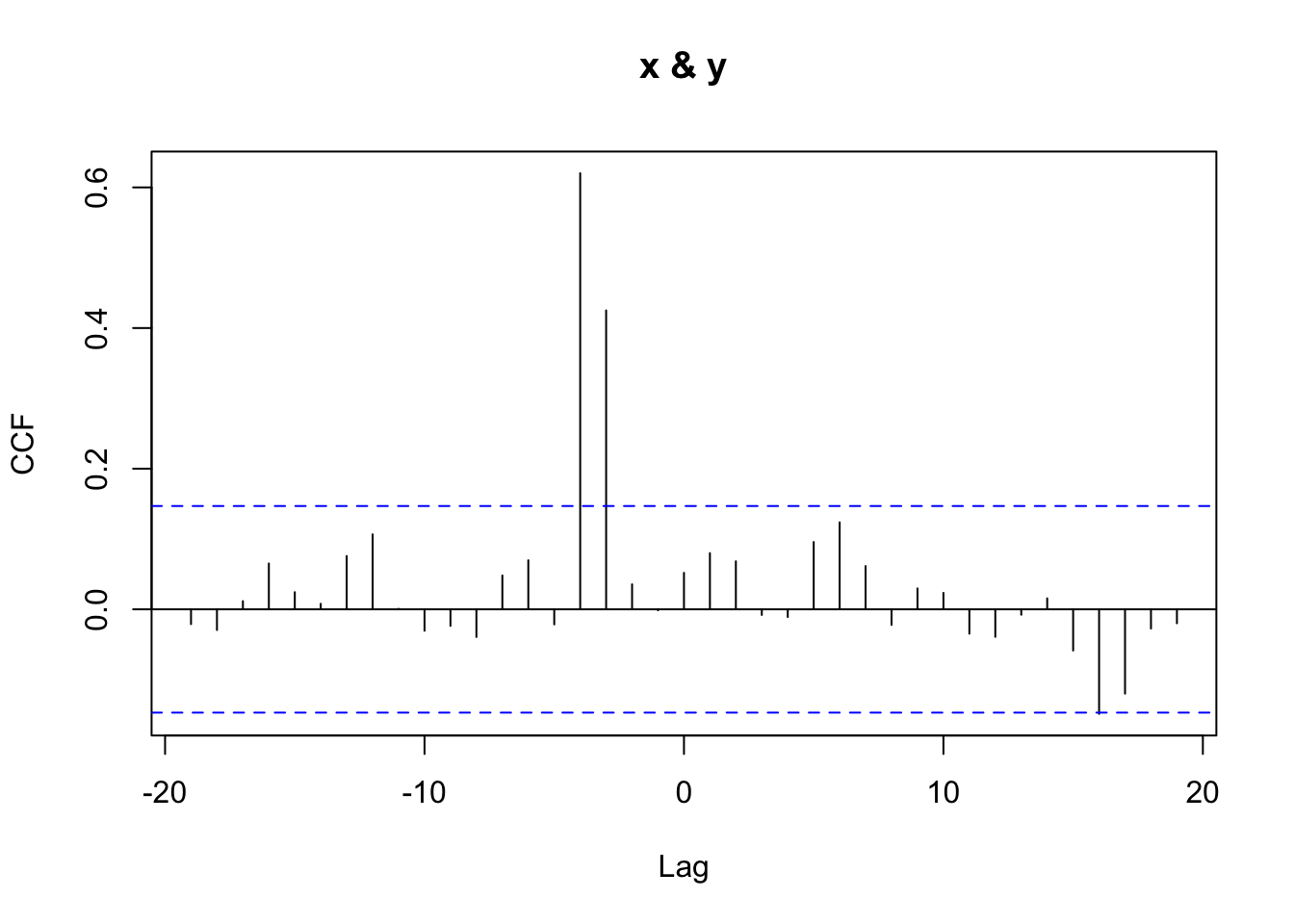
prewhiten(x2_series, y2_series)
prew## $ccf
##
## Autocorrelations of series 'X', by lag
##
## -19 -18 -17 -16 -15 -14 -13 -12 -11 -10 -9
## -0.021 -0.029 0.012 0.065 0.024 0.008 0.076 0.107 0.001 -0.031 -0.024
## -8 -7 -6 -5 -4 -3 -2 -1 0 1 2
## -0.039 0.048 0.070 -0.021 0.620 0.425 0.036 -0.001 0.052 0.080 0.068
## 3 4 5 6 7 8 9 10 11 12 13
## -0.008 -0.011 0.096 0.124 0.062 -0.022 0.030 0.023 -0.035 -0.039 -0.008
## 14 15 16 17 18 19
## 0.016 -0.059 -0.149 -0.120 -0.027 -0.020
##
## $model
##
## Call:
## ar.ols(x = x)
##
## Coefficients:
## 1 2 3 4 5 6 7 8
## 0.6362 0.1109 0.0496 -0.1533 -0.0240 -0.0499 0.2041 0.0221
## 9 10 11 12 13 14
## -0.0990 -0.0981 0.1703 -0.0558 -0.0812 0.1179
##
## Intercept: 0.006091 (0.06307)
##
## Order selected 14 sigma^2 estimated as 0.7336Considering the autocorrelated structure of the series, the true model can be written as follows:
\[ \begin{split} y_t &= 15 + 0.8 x_{t-3} + 1.5 x_{t-4} + \eta_t \\ \eta_t &= 0.7 \eta_{t-1} + \epsilon_t + 0.6 \epsilon_{t-1} \\ \epsilon &\sim N(0, 1) \end{split} \]
It is possible to calculate the regression using the lm function, calculating the lagged variables by hand, or to use the dynml library and function.
# Calculate the lagged variables by hand and apply the lm function...
x2Lagged <- cbind(
xLag0 = x2_series,
xLag3 = stats::lag(x2_series,-3),
xLag4 = stats::lag(x2_series,-4))
xy2_series <- ts.union(y2_series, x2Lagged)
lm2 <- lm(xy2_series[,1] ~ xy2_series[,3:4])
summary(lm2) # AIC: 821.45##
## Call:
## lm(formula = xy2_series[, 1] ~ xy2_series[, 3:4])
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.9200 -1.4508 0.0667 1.5395 5.1083
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 14.9005 0.1486 100.273 < 2e-16 ***
## xy2_series[, 3:4]x2Lagged.xLag3 1.0407 0.1595 6.523 6.14e-10 ***
## xy2_series[, 3:4]x2Lagged.xLag4 1.5171 0.1599 9.488 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.028 on 189 degrees of freedom
## (12 observations deleted due to missingness)
## Multiple R-squared: 0.6735, Adjusted R-squared: 0.67
## F-statistic: 194.9 on 2 and 189 DF, p-value: < 2.2e-16
# ... or use the dynml function
dynlm.fit2 <- dynlm(y2_series ~ L(x2_series, 3) + L(x2_series, 4))
summary(dynlm.fit2)##
## Time series regression with "ts" data:
## Start = 5, End = 196
##
## Call:
## dynlm(formula = y2_series ~ L(x2_series, 3) + L(x2_series, 4))
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.9200 -1.4508 0.0667 1.5395 5.1083
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 14.9005 0.1486 100.273 < 2e-16 ***
## L(x2_series, 3) 1.0407 0.1595 6.523 6.14e-10 ***
## L(x2_series, 4) 1.5171 0.1599 9.488 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.028 on 189 degrees of freedom
## Multiple R-squared: 0.6735, Adjusted R-squared: 0.67
## F-statistic: 194.9 on 2 and 189 DF, p-value: < 2.2e-16The estimated model is the following:
\[ \begin{split} y_t &= 14.9005 + 1.0407 x_{t-3} + 1.5171 x_{t-4} + \epsilon_t \\ \epsilon &\sim N(0, 2.028^2) \end{split} \]
The original series can also be visualized with the fitted values (the values resulting from the model), to visually inspect how well the model represents the original series. The differences between the original and the fitted series are the residuals.
lm2d <- ts.intersect(na.omit(xy2_series[,1]), lm2$fitted.values)
plot.ts(lm2d, plot.type = "single", col=c("orange","blue"),
lty=c(1,4), lwd=c(1,1),
main = "'Classic' Linear Model - Original (orange) and Fitted series (blue)") 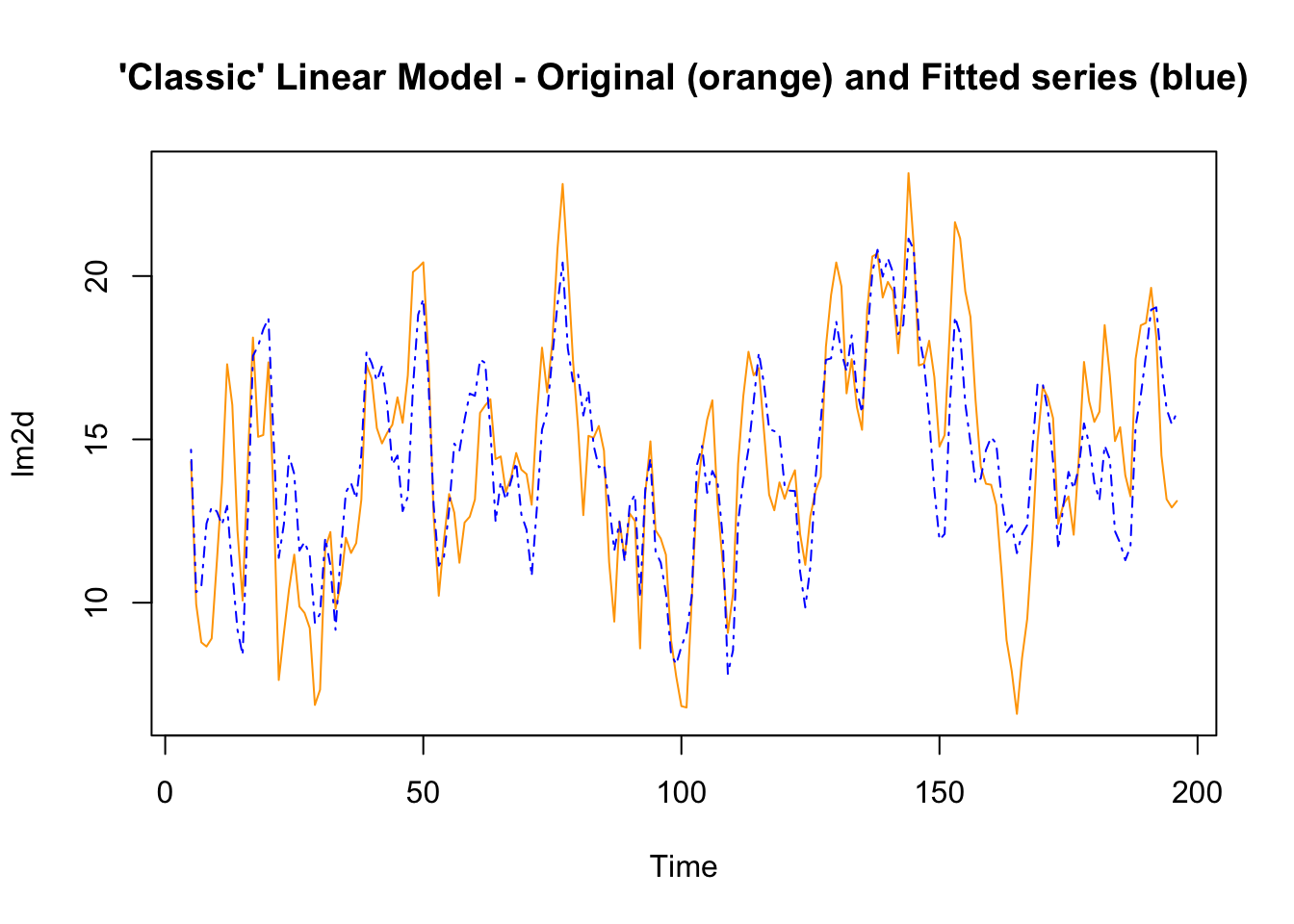
The diagnostic plots of the residuals show the presence of autocorrelation, and the Breusch-Godfrey test is highly significant (its value is far lower than the critical value \(\alpha = 0.05\))
checkresiduals(lm2)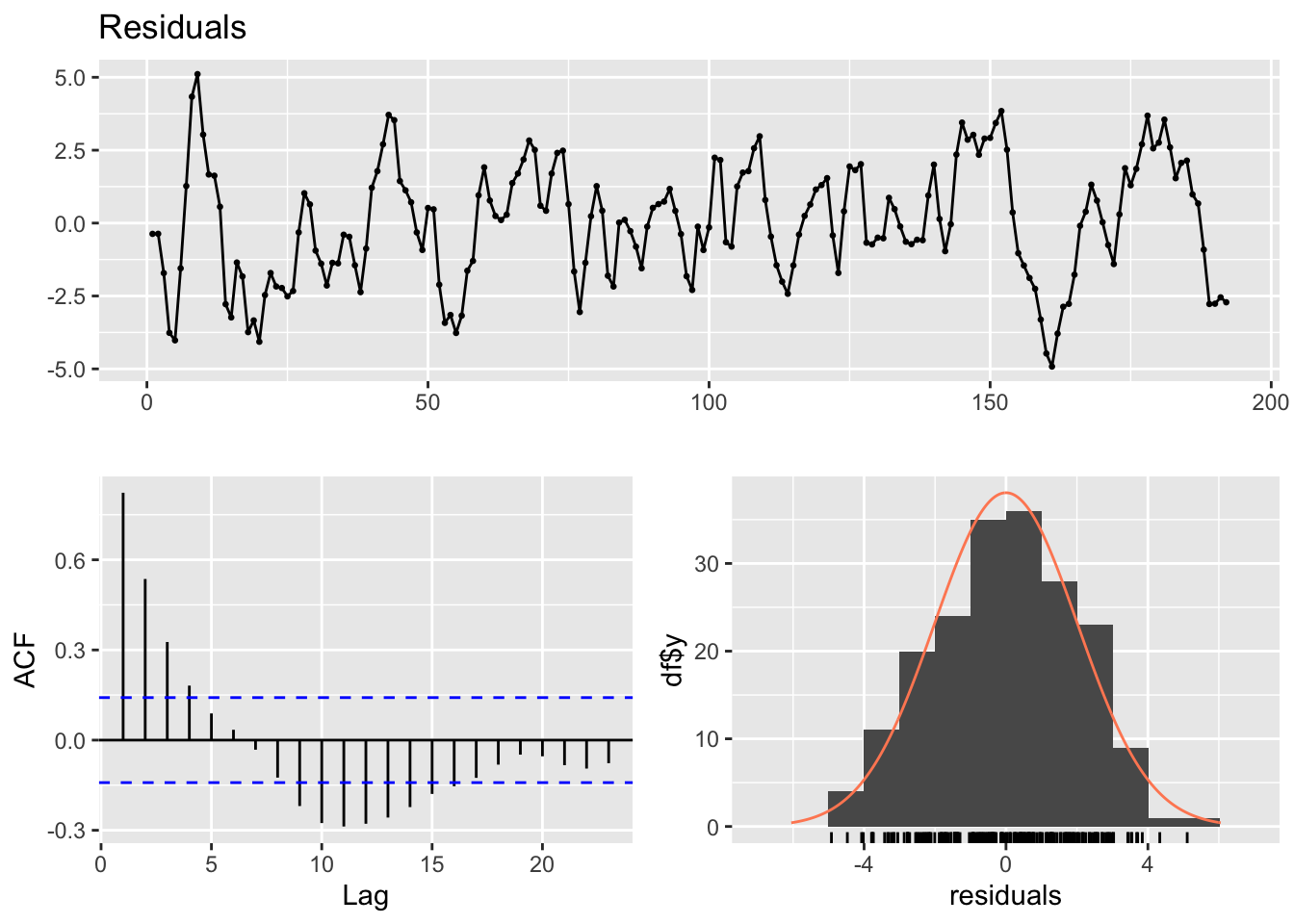
##
## Breusch-Godfrey test for serial correlation of order up to 10
##
## data: Residuals
## LM test = 149.45, df = 10, p-value < 2.2e-16
pacf(lm2$residuals)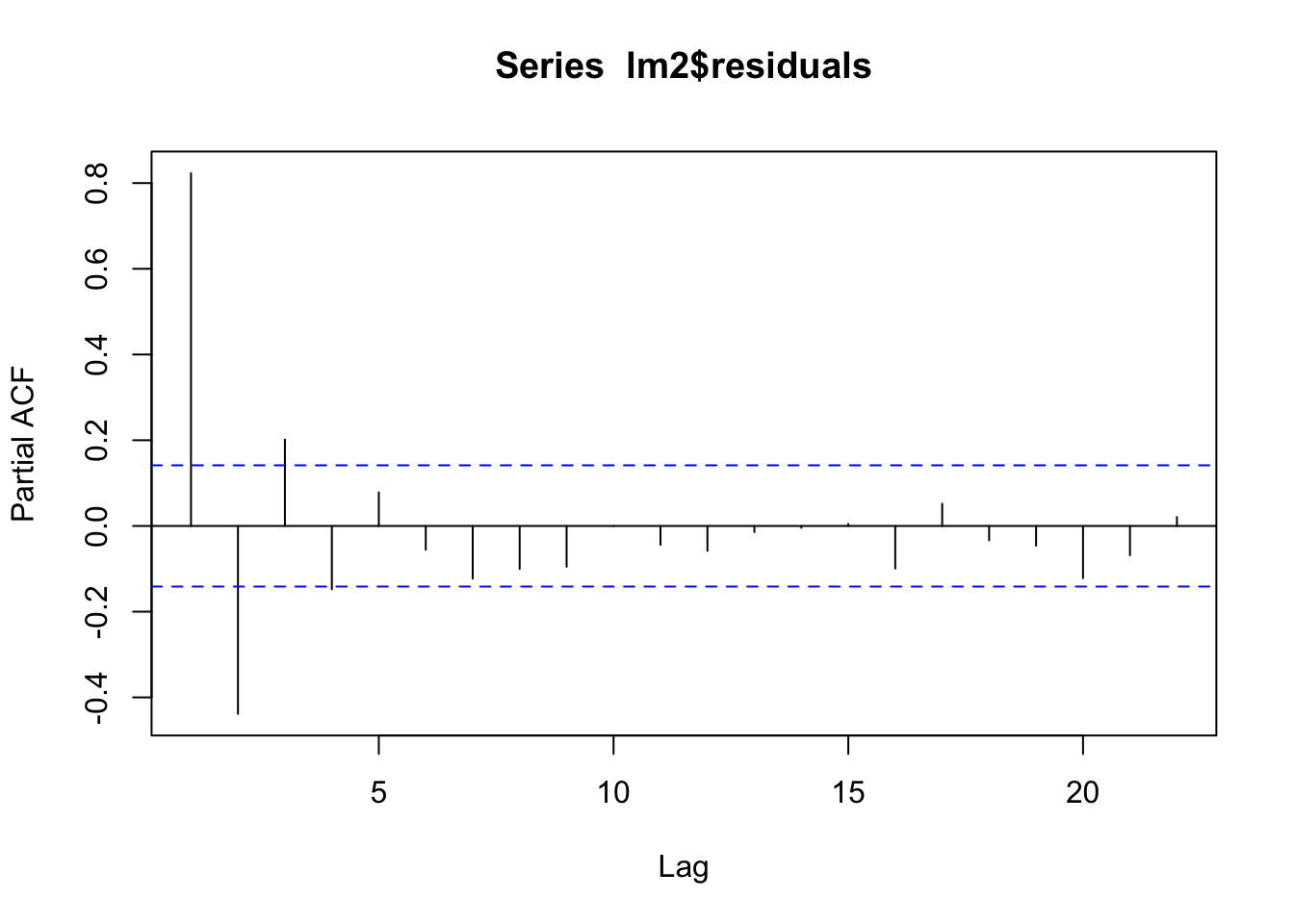
In this case, it’s better to take into account the residuals’ autocorrelation by using a regression model capable to handle autocorrelated time series structures.
In the previous chapter we said that ARIMA models are a special type of regression model, in which the dependent variable is the time series itself, and the independent variables are all lags of the time series. This model is capable to take into account the autocorrelated structure of time series.
ARIMA is a modeling technique that can be applied to a single time series, but it can be extended to include additional, exogenous variables. The ARIMA model including exogenous regressors (i.e.: other time series besides the lagged dependent variable) is like a multiple regression models for time series. In particular, it can be considered a regression model capable to control for autocorrelation in residuals.
It is possible to use more than one option to fit an ARIMA model with external regressors. A convenient option is provided by the function auto.arima, in the package forecast. This library has an argument xreg which can be use with a numerical vector or matrix of external regressors, which must have the same number of rows as y (see ?auto.arima).
arima1 <- auto.arima(xy2_series[,1], xreg = xy2_series[,3:4])
arima1## Series: xy2_series[, 1]
## Regression with ARIMA(1,0,1) errors
##
## Coefficients:
## ar1 ma1 intercept x2Lagged.xLag3 x2Lagged.xLag4
## 0.6863 0.6491 14.8532 0.9506 1.5732
## s.e. 0.0555 0.0528 0.3607 0.0757 0.0762
##
## sigma^2 = 0.9482: log likelihood = -265.76
## AIC=543.52 AICc=543.97 BIC=563.06The resulting model seems to be more appropriate than the previous one, fitted by using just a “classic” linear regression. This is clear also by comparing the two models through the AIC criterion (Akaike information criterion). The AIC value is used to compare the goodness-of-fit of different models fitted to the same dataset. The lower the AIC value, the better the fit (see also the next paragraph).
The auto.arima function prints the AIC value by default, while this value is not given with the lm function. To get it, we need to use the AIC function.
AIC(lm2)## [1] 821.4495In this case, the ARIMA regression model results a far better model (AIC=543.52) compared with the classic linear model (AIC=821.45).
\[ \begin{split} y_t &= 14.8532 + 0.9506 x_{t-3} + 1.5732 x_{t-4} + \eta_t \\ \eta_t &= 0.6863 \eta_{t-1} + \epsilon_t + 0.6491 \epsilon_{t-1} \\ \epsilon &\sim N(0, 0.9482) \end{split} \]
Diagnostic analysis of the residuals, shows that there is no concerning sign of autocorrelation in the residuals, which looks like white noise. Also the test for autocorrelated errors is not significant (the default test for autocorrelation when testing an ARIMA models with external regressors in the forecast package is the Ljung-Box test)3).
checkresiduals(arima1)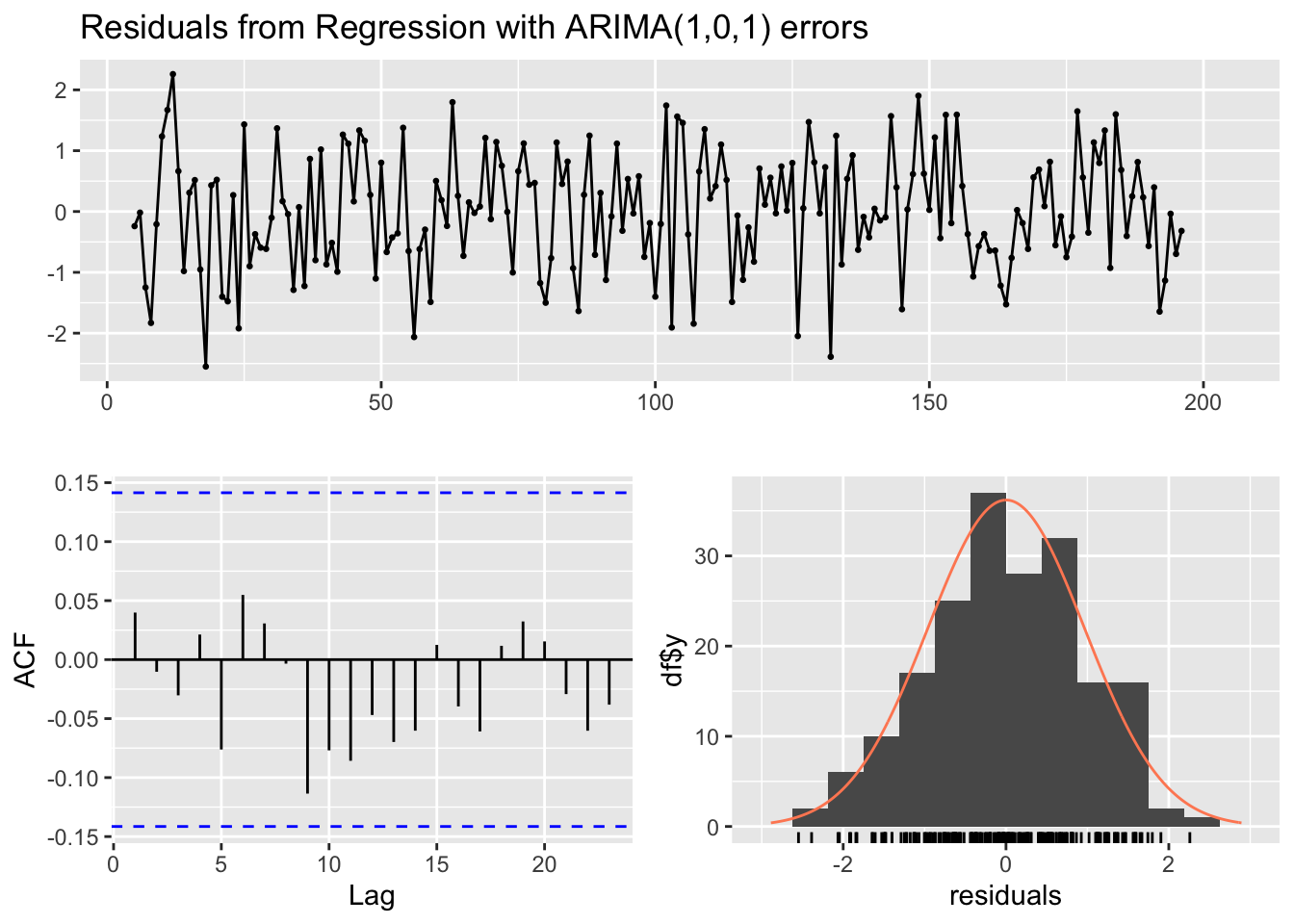
##
## Ljung-Box test
##
## data: Residuals from Regression with ARIMA(1,0,1) errors
## Q* = 6.3861, df = 8, p-value = 0.6041
##
## Model df: 2. Total lags used: 10Also by visually inspect the original series along with the fitted series (the values resulting from the model), it can be seen that the model is better than the previous one.
arima1d <- ts.intersect(na.omit(xy2_series[,1]), arima1$fitted)
plot.ts(arima1d, plot.type = "single", col=c("orange","blue"),
lty=c(1,4), lwd=c(1,1),
main = "ARIMA errors model - Original (orange) and Fitted series (blue)") 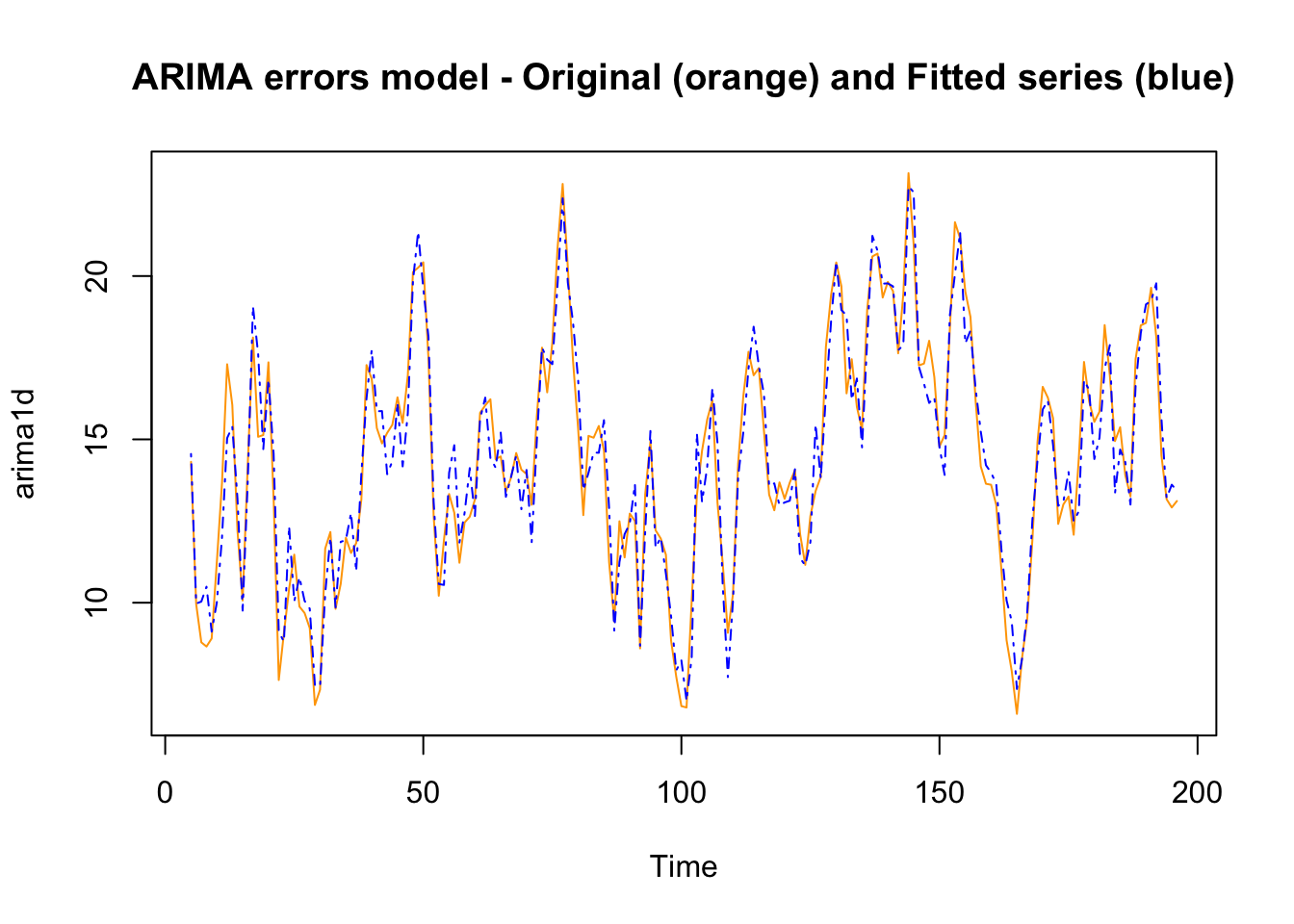
We can also compare the fitted versus original values by using a scatterplot. A better model produces a thinner diagonal line.
par(mfrow=c(1,2))
plot(na.omit(xy2_series[,1]), lm2$fitted.values, main = "LM", xlab="Original", ylab="Fitted")
plot(na.omit(xy2_series[,1]), arima1$fitted, main = "ARIMA regression model", xlab="Original", ylab="Fitted")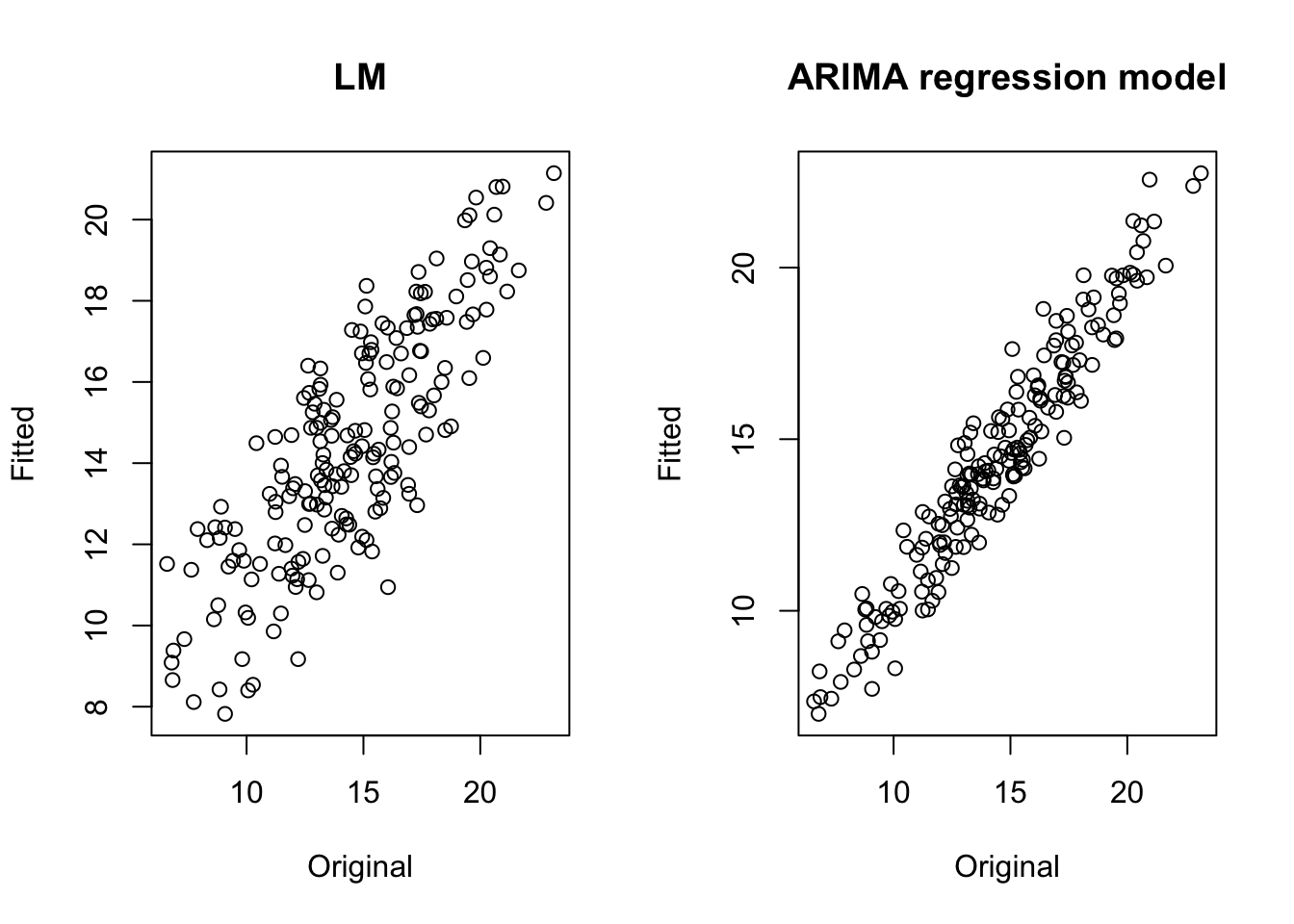 The auto.arima function does not give the statistical significance of the coefficients (the approach adopted by the forecast library is different, based on the choice of the best model to do forecasting), but it is possible to get that by using the function coeftest in the library lmtest.
The auto.arima function does not give the statistical significance of the coefficients (the approach adopted by the forecast library is different, based on the choice of the best model to do forecasting), but it is possible to get that by using the function coeftest in the library lmtest.
##
## z test of coefficients:
##
## Estimate Std. Error z value Pr(>|z|)
## ar1 0.686330 0.055525 12.361 < 2.2e-16 ***
## ma1 0.649134 0.052850 12.283 < 2.2e-16 ***
## intercept 14.853152 0.360689 41.180 < 2.2e-16 ***
## x2Lagged.xLag3 0.950588 0.075705 12.557 < 2.2e-16 ***
## x2Lagged.xLag4 1.573242 0.076224 20.640 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 19.2.4 Count regression models
The models described above are mostly used with continuous variables (expressed as numeric or double in the R data format). However, it is often the case that time series are composed of integer values, or count data (expressed as integer).
Sometimes, the above mentioned methods work well also with this type of data (for instance, when the counts are large). Other times, time series model developed for count data can be a better choice (for instance, when the series include mostly small integer values).
Two of the most common statistical models to deal with count data are based on the Poisson and the Negative Binomial distributions. These probability distributions are the ones that are usually employed to model count data.
There are a few libraries to fit count time series regression models in R. We take into consideration tscount, and its function tsglm.
We consider, as an example of the tscount function to fit count time series regression models, the dataset “Seatbelts” (monthly number of killed drivers of light goods vehicles in Great Britain between January 1969 and December 1984), following the paper that describes the tscount library.
The authors of the package write in the paper (par. 7.2) describing the library:
This time series is part of a dataset which was first considered by Harvey and Durbin (1986) for studying the effect of compulsory wearing of seatbelts introduced on 31 January 1983. The dataset, including additional covariates, is available in R in the object Seatbelts. In their paper Harvey and Durbin (1986) analyze the numbers of casualties for drivers and passengers of cars, which are so large that they can be treated with methods for continuous-valued data. The monthly number of killed drivers of vans analyzed here is much smaller (its minimum is 2 and its maximum 17) and therefore methods for count data are to be preferred.
data("Seatbelts")
timeseries <- Seatbelts[, "VanKilled"]
regressors <- cbind(PetrolPrice = Seatbelts[, c("PetrolPrice")],
linearTrend = seq(along = timeseries))
timeseries_until1981 <- window(timeseries, end = c(1981, 12))
regressors_until1981 <- window(regressors, end = c(1981, 12))We are going to fit a model aimed at capturing a first order autoregressive AR(1) term and a yearly seasonality by a 12th order autoregressive term.
par(mfrow=c(2,2))
plot.ts(timeseries, main="")
hist(timeseries, main="")
acf(timeseries, main="")
pacf(timeseries, main="")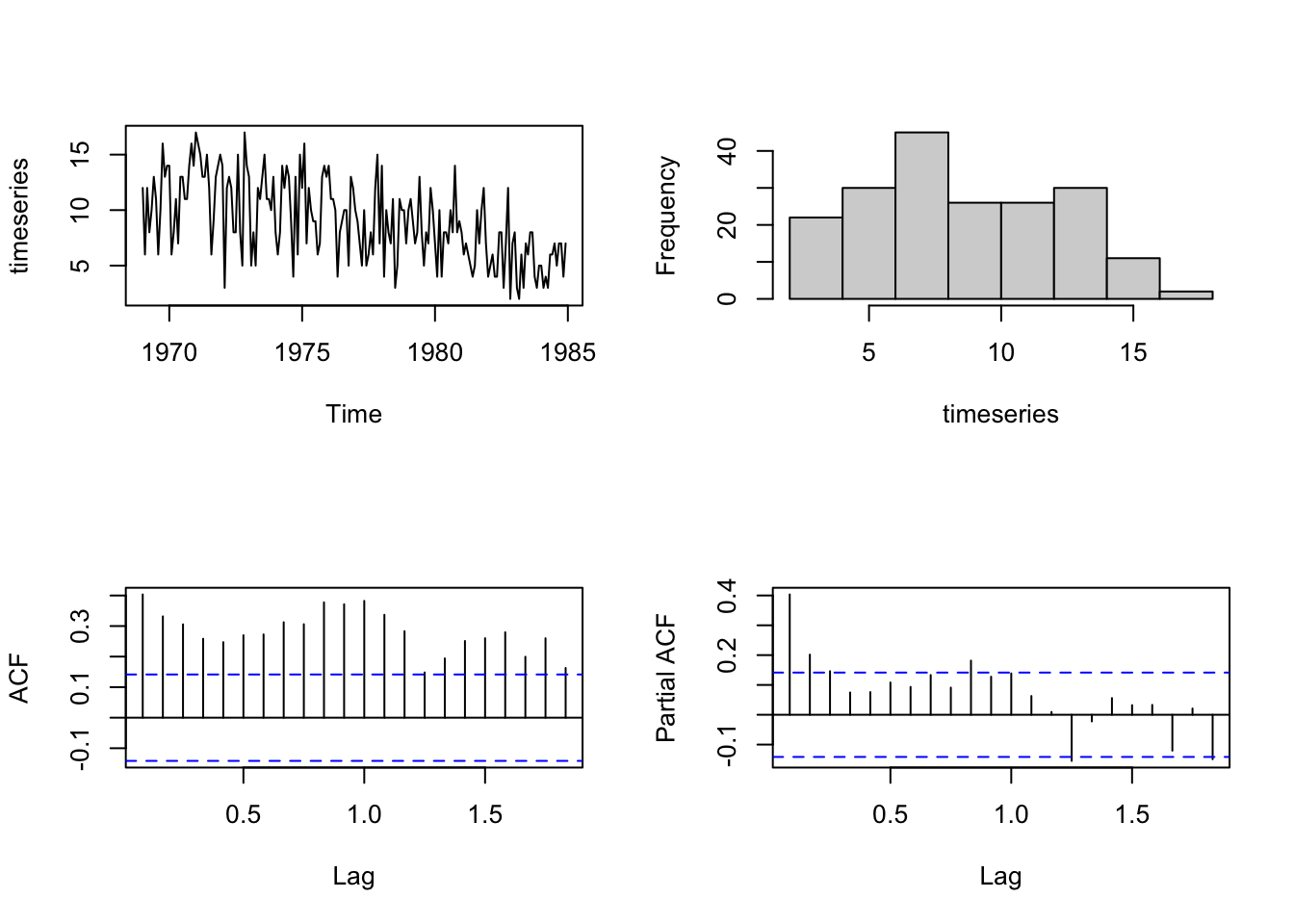
The function tsglm allows users to declare the autoregressive and seasonal autoregressive terms in a convenient way (in the following part of the function: model = list(past_obs = c(1, 12))).
poisson_fit <- tsglm(timeseries_until1981,
model = list(past_obs = c(1, 12)),
xreg = regressors_until1981,
distr = "poisson", link = "log")It is possible to check the residuals with the usual plots.
par(mfrow=c(2,2))
plot(poisson_fit$residuals, main="")
hist(poisson_fit$residuals, main="")
acf(poisson_fit$residuals, main="")
pacf(poisson_fit$residuals, main="")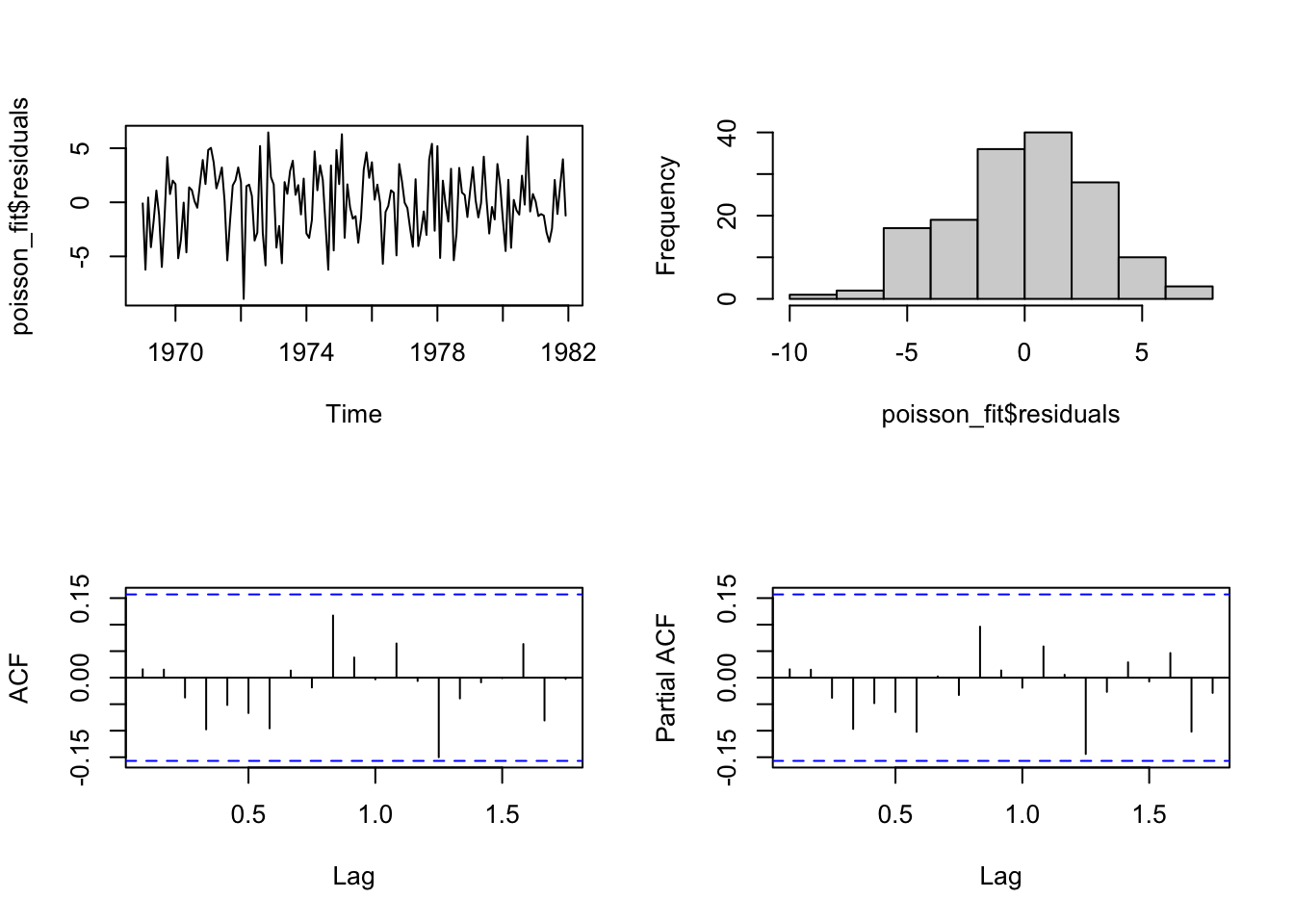
The function summary can be used to get the parameter estimates for the model (in this case the function can also employ a parametric bootstrap procedure (B) to obtain standard errors and confidence intervals of the regression parameters. The authors use B=500 in the original paper, since in their experience this value yields stable results. Higher B values can be more precise but require time to be calculated).
summary(poisson_fit)##
## Call:
## tsglm(ts = timeseries_until1981, model = list(past_obs = c(1,
## 12)), xreg = regressors_until1981, link = "log", distr = "poisson")
##
## Coefficients:
## Estimate Std.Error CI(lower) CI(upper)
## (Intercept) 1.83284 0.367830 1.11191 2.55377
## beta_1 0.08672 0.080913 -0.07187 0.24530
## beta_12 0.15288 0.084479 -0.01269 0.31846
## PetrolPrice 0.83069 2.303555 -3.68420 5.34557
## linearTrend -0.00255 0.000653 -0.00383 -0.00127
## Standard errors and confidence intervals (level = 95 %) obtained
## by normal approximation.
##
## Link function: log
## Distribution family: poisson
## Number of coefficients: 5
## Log-likelihood: -396.1765
## AIC: 802.3529
## BIC: 817.6022
## QIC: 802.3529
# summary(poisson_fit, B=500) # to use the bootstrap procedureThe model is as follows:
\[ log(\lambda_t) = 1.83 + 0.09Y_{t-1} + 0.15Y_{t-12} + 0.83X_t - 0.003t \] In the above equation notice that, the Poisson regression, models the logarithm of the Y values at times t (expressed as \(log(\lambda_t)\)).
Another example (using the dataset you can download here):
library(tidyverse)
gtrend_fakenews_qanon <- read_csv("data/gtrend_fakenews_qanon.csv",
col_types = cols(date = col_date(format = "%Y-%m"),
fake_news = col_integer(),
qanon = col_integer()))
# head(gtrend_fakenews_qanon$date,1) # 2015-01-01
# tail(gtrend_fakenews_qanon$date,1) # 2020-12-01
fake_news <- ts(gtrend_fakenews_qanon$fake_news,
start = c(2015,1), end = c(2020,12), frequency = 12)
qanon <- ts(gtrend_fakenews_qanon$qanon,
start = c(2015,1), end = c(2020,12), frequency = 12)
layout(matrix(c(1,1,2,3,4,5), 2,3, byrow=T))
plot.ts(qanon, main="")
hist(qanon, main="")
acf(qanon, 48, main="")
pacf(qanon, 48, main="")
qanon_fake_ccf <- prewhiten(fake_news, qanon, main="")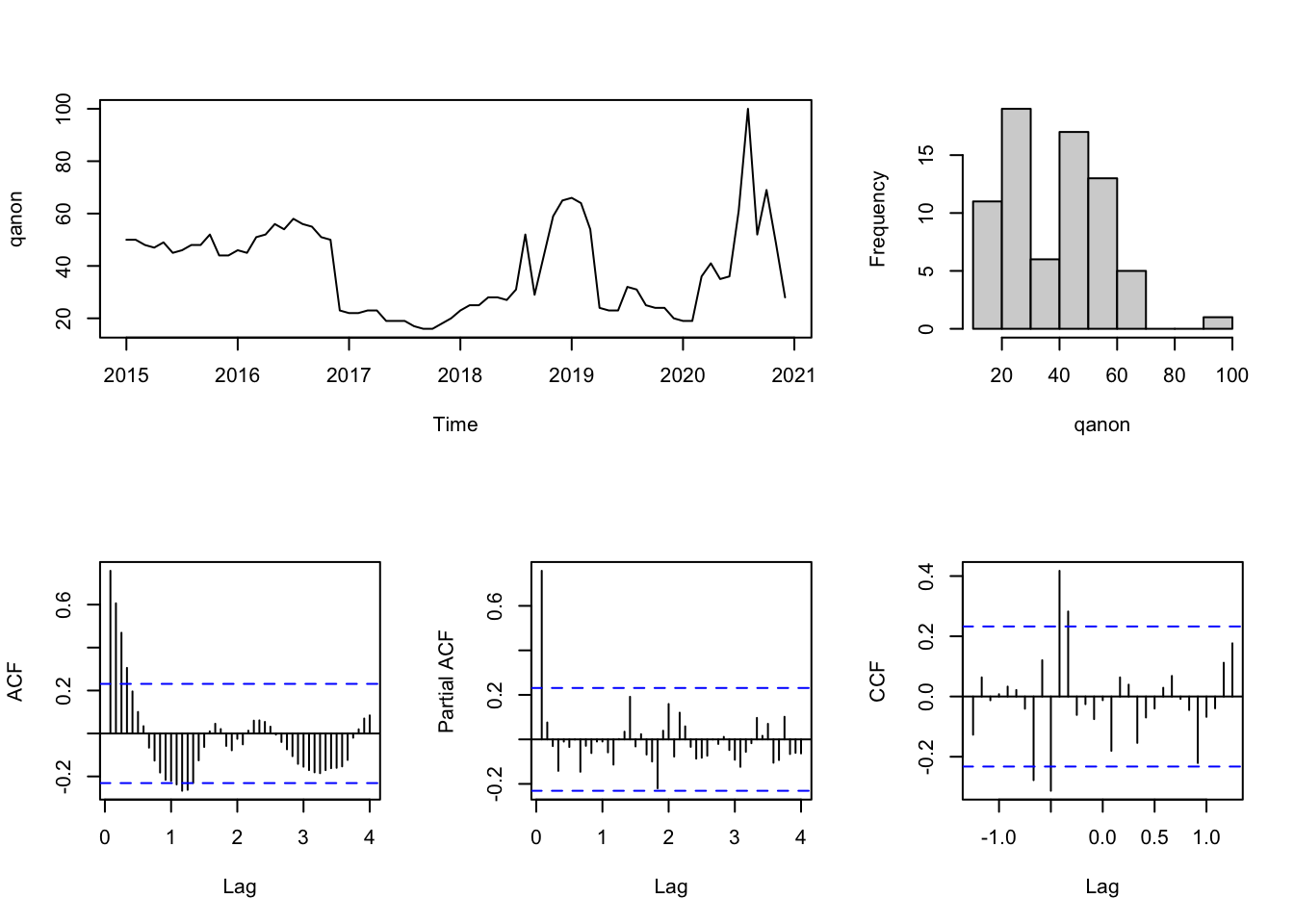
qanon_fake_ccf$ccf##
## Autocorrelations of series 'X', by lag
##
## -1.2500 -1.1667 -1.0833 -1.0000 -0.9167 -0.8333 -0.7500 -0.6667 -0.5833
## -0.127 0.064 -0.013 0.008 0.033 0.022 -0.041 -0.278 0.120
## -0.5000 -0.4167 -0.3333 -0.2500 -0.1667 -0.0833 0.0000 0.0833 0.1667
## -0.313 0.417 0.282 -0.061 -0.025 -0.075 -0.012 -0.180 0.063
## 0.2500 0.3333 0.4167 0.5000 0.5833 0.6667 0.7500 0.8333 0.9167
## 0.039 -0.154 -0.070 -0.040 0.029 0.068 -0.008 -0.045 -0.221
## 1.0000 1.0833 1.1667 1.2500
## -0.068 -0.039 0.112 0.177
reg <- cbind(fake_news_lag4 = stats::lag(fake_news, -4),
fake_news_lag5 = stats::lag(fake_news, -5),
fake_news_lag6 = stats::lag(fake_news, -6))
# NA values derives from the application of the "lag" function
# and have to be removed, since the regression function cannot
# work properly with them
reg <- na.omit(reg)
# start(reg) # 2015, 6
# end(reg) # 2021, 4
reg <- window(reg, start = c(2015, 7), end = c(2020, 12))
qanon <- window(qanon, start = c(2015, 7), end = c(2020, 12))
poisson_gtrend_fit <- tsglm(qanon,
model = list(past_obs = 1),
xreg = reg,
distr = "poisson", link = "log")
layout(matrix(c(1,1,2,3,4,5), 3,2, byrow=T))
plot(poisson_gtrend_fit$residuals, main="")
hist(poisson_gtrend_fit$residuals, main="")
acf(poisson_gtrend_fit$residuals, main="")
pacf(poisson_gtrend_fit$residuals, main="")
plot(as.vector(poisson_gtrend_fit$response),
as.vector(poisson_gtrend_fit$fitted.values),
xlab="response", ylab="fitted")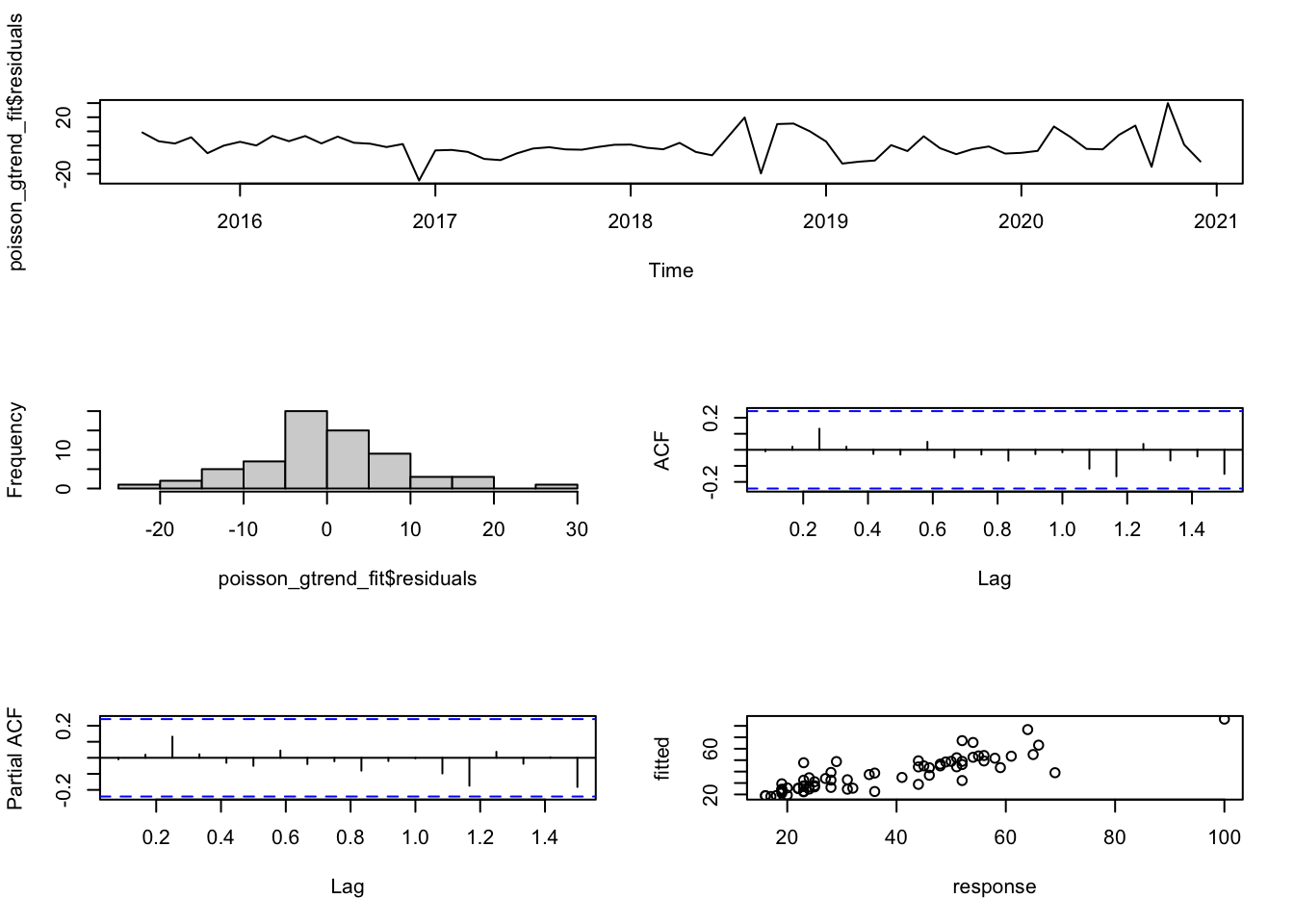
Besides checking the residuals, it is possible to plot the PIT histogram, provided by the function pit in tscount:
A PIT histogram is a tool for evaluating the statistical consistency between the probabilistic forecast and the observation. The predictive distributions of the observations are compared with the actual observations. If the predictive distribution is ideal the result should be a flat PIT histogram with no bin having an extraordinary high or low level. For more information about PIT histograms see the references listed below.
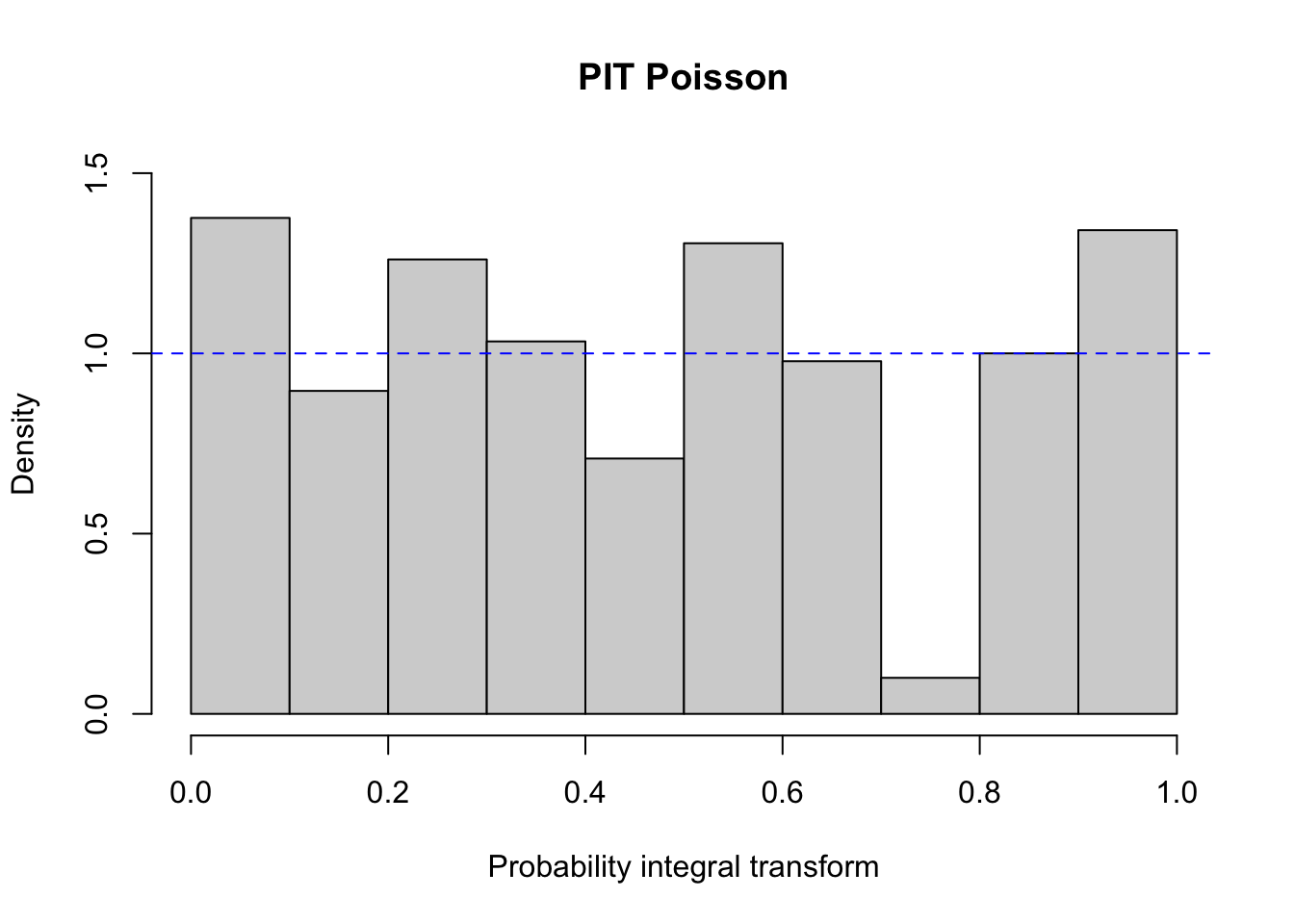
In the library are included other diagnostic tools and metrics that can help choosing between poisson and negative binomial models (see the paper for further information).
The function summary prints the coefficients of the model and their confidence interval.
summary(poisson_gtrend_fit)##
## Call:
## tsglm(ts = qanon, model = list(past_obs = 1), xreg = reg, link = "log",
## distr = "poisson")
##
## Coefficients:
## Estimate Std.Error CI(lower) CI(upper)
## (Intercept) 0.58373 0.18036 0.230232 0.9372
## beta_1 0.83746 0.04834 0.742715 0.9322
## fake_news_lag4 0.00892 0.00274 0.003546 0.0143
## fake_news_lag5 0.00638 0.00354 -0.000554 0.0133
## fake_news_lag6 -0.01617 0.00272 -0.021506 -0.0108
## Standard errors and confidence intervals (level = 95 %) obtained
## by normal approximation.
##
## Link function: log
## Distribution family: poisson
## Number of coefficients: 5
## Log-likelihood: -239.6582
## AIC: 489.3163
## BIC: 500.2646
## QIC: 489.31639.3 Model Selection (AIC, AICc, BIC)
Statistical modeling is, usually, a recursive process that requires to fit several different models and, eventually, to select the most appropriate one. For instance, the Box and Jenkins approach employed to find an appropriate ARIMA model for a time series (see the previous chapter), requires the fitting of multiple models to find the most suitable one based on the data. Similarly, the “auto.arima” function in the library forecast, that automatizes the search for an appropriate ARIMA model, conducts a search over possible model.
To compare the models and select the most appropriate one, it is necessary to use some criteria. In the example above we have employed the AIC criterion. Other similar criteria are the AICc, and the BIC. They all can be used to find the most appropriate model, by comparing the goodness-of-fit of different models fitted to the same dataset. For instance, the documentation of the “auto.arima” function says that the function “returns best ARIMA model according to either AIC, AICc or BIC value”.
The AIC criterion is the acronym for Akaike information criterion). The lower the AIC value, the better the fit (see also the next paragraph).
The AICc criterion, is the same, but with a correction for small sample size. When the sample is small it can be used in place of the AIC criterion. As the sample size increases, the AICc converges to the AIC.
The BIC criterion is the Bayesian Information Criterion (or Schwartz’s Bayesian Criterion) and has a stronger penalty than the AIC for overparametrized models (more complex models, with several predictors).
These criteria can also be used when searching for an appropriate regression model, to compare several different models including different lags of the variables.
When comparing models by using these criteria, it is important that the models are fitted to the same dataset, otherwise the results are not comparable. This is an important aspect to take into account when using lagged predictors. For instance, you may want to try a model including one lagged predictor \(x_{t-1}\) and a model including two lagged predictors \(x_{t-1}\) and \(x_{t-2}\), and to compare them in order to select the best one according to AIC, AICc or the BIC criterion. However, when you add lagged predictor you loose data points.
x_example <- ts(rnorm(40))
y_example <- ts(rnorm(40))
example_data <- cbind(y = y_example,
xLag0 = x_example,
xLag1 = stats::lag(x_example, -1),
xLag2 = stats::lag(x_example, -2))
example_data## Time Series:
## Start = 1
## End = 42
## Frequency = 1
## y xLag0 xLag1 xLag2
## 1 1.075501365 0.48505236 NA NA
## 2 -0.276740732 -1.20993027 0.48505236 NA
## 3 -0.646751445 0.01724609 -1.20993027 0.48505236
## 4 0.102585633 0.70085715 0.01724609 -1.20993027
## 5 -0.072519610 -0.40170226 0.70085715 0.01724609
## 6 1.619712305 -0.48727576 -0.40170226 0.70085715
## 7 0.687751998 -0.76436248 -0.48727576 -0.40170226
## 8 0.234929596 2.97223380 -0.76436248 -0.48727576
## 9 -0.430528202 -0.43578545 2.97223380 -0.76436248
## 10 0.638039146 -1.35197954 -0.43578545 2.97223380
## 11 -0.217226469 -0.52868886 -1.35197954 -0.43578545
## 12 0.020494309 -0.06027948 -0.52868886 -1.35197954
## 13 -1.913357840 -0.03222441 -0.06027948 -0.52868886
## 14 -0.526191144 0.55290101 -0.03222441 -0.06027948
## 15 0.416282618 -0.25966064 0.55290101 -0.03222441
## 16 0.457627862 -1.01400343 -0.25966064 0.55290101
## 17 -0.275639625 -0.86452761 -1.01400343 -0.25966064
## 18 -0.353882346 0.11040086 -0.86452761 -1.01400343
## 19 -0.901762561 -0.02452574 0.11040086 -0.86452761
## 20 -1.052145243 -2.51548495 -0.02452574 0.11040086
## 21 0.832626641 0.44375488 -2.51548495 -0.02452574
## 22 0.056411159 1.56218440 0.44375488 -2.51548495
## 23 0.838708652 0.97180894 1.56218440 0.44375488
## 24 0.344611778 1.58747428 0.97180894 1.56218440
## 25 -1.088605832 -1.84530863 1.58747428 0.97180894
## 26 -0.527820628 -1.27107477 -1.84530863 1.58747428
## 27 3.061137014 2.03899229 -1.27107477 -1.84530863
## 28 -0.520213835 -0.72914933 2.03899229 -1.27107477
## 29 0.248244201 0.93447357 -0.72914933 2.03899229
## 30 0.046969519 -0.75324932 0.93447357 -0.72914933
## 31 0.249449596 -0.68448064 -0.75324932 0.93447357
## 32 1.041843001 -0.59473197 -0.68448064 -0.75324932
## 33 -0.338376495 -0.12412231 -0.59473197 -0.68448064
## 34 0.201287727 -1.39014027 -0.12412231 -0.59473197
## 35 0.602711731 -1.23556534 -1.39014027 -0.12412231
## 36 -0.225018148 -1.28500792 -1.23556534 -1.39014027
## 37 -0.010113590 -1.05225339 -1.28500792 -1.23556534
## 38 -0.193597244 1.36496602 -1.05225339 -1.28500792
## 39 0.009188137 -1.07721180 1.36496602 -1.05225339
## 40 1.441899269 0.67538151 -1.07721180 1.36496602
## 41 NA NA 0.67538151 -1.07721180
## 42 NA NA NA 0.67538151Thus, when you fit models with different lags, you have to fit them on the same dataset. In this case, for instance, you have to skip the NA rows, and use just the rows from 3 to 40.
# Restrict data so models use same fitting period
fit1 <- auto.arima(example_data[3:40,1], xreg=example_data[3:40,2])
fit2 <- auto.arima(example_data[3:40,1], xreg=example_data[3:40,2:3])
fit3 <- auto.arima(example_data[3:40,1], xreg=example_data[3:40,2:4])Then you can compare the model, for instance, using the AIC criterion, and choose the model with the smallest value.
fit1$aic## [1] 95.11836
fit2$aic## [1] 94.31932
fit3$aic## [1] 96.07911Finally, you fit the model using all the available data.
fit1 <- auto.arima(example_data[,1], xreg=example_data[,2])
fit1## Series: example_data[, 1]
## Regression with ARIMA(0,0,0) errors
##
## Coefficients:
## xreg
## 0.2447
## s.e. 0.1120
##
## sigma^2 = 0.6511: log likelihood = -47.67
## AIC=99.34 AICc=99.66 BIC=102.72Besides these criteria, there are also other strategies for model selection.
9.4 Some examples in the literature
There are several examples of the use of time series regression models in the literature in the field of communication science.
For instance, in The Event-Centered Nature of Global Public Spheres: The UN Climate Change Conferences, Fridays for Future, and the (Limited) Transnationalization of Media Debates4, the authors examined whether the UN climate change conferences are conducive to an emergence of a transnational public sphere by triggering issue convergence and increased transnational interconnectedness across national media debates. They authors detail the method they follows in this way:
[…] Given the autoregressive nature and other properties of time series, an ordinary least squares regression analysis would violate the normality of error and the independence of observations assumption (Wells et al., 2019). Instead, we applied the dynamic regression approach (Gujarati & Porter, 2009; Hyndman & Athanasopoulos, 2018), which assumes that the error term follows an autoregressive integrated moving average (ARIMA) model (…). we found the best ARIMA structure of the error term by using the auto.arima function from the forecast R package (Hyndman & Khandakar, 2008). It searches for an ARIMA structure that can explain the most variance according to the Akaike information criterion (Akaike, 1973).
In this case they use the term “dynamic regression” to refer to a time series regression with ARIMA errors, but they did not include lagged values of their variables, thus analyzing contemporary relationships between variables.
The found, for instance, that events taking place on a supranational level of governance (…) consistently led to spikes in media attention across countries. In contrast, a bottom-up effort such as Fridays for Future showed an inconsistent relationship with media attention across the four countries.
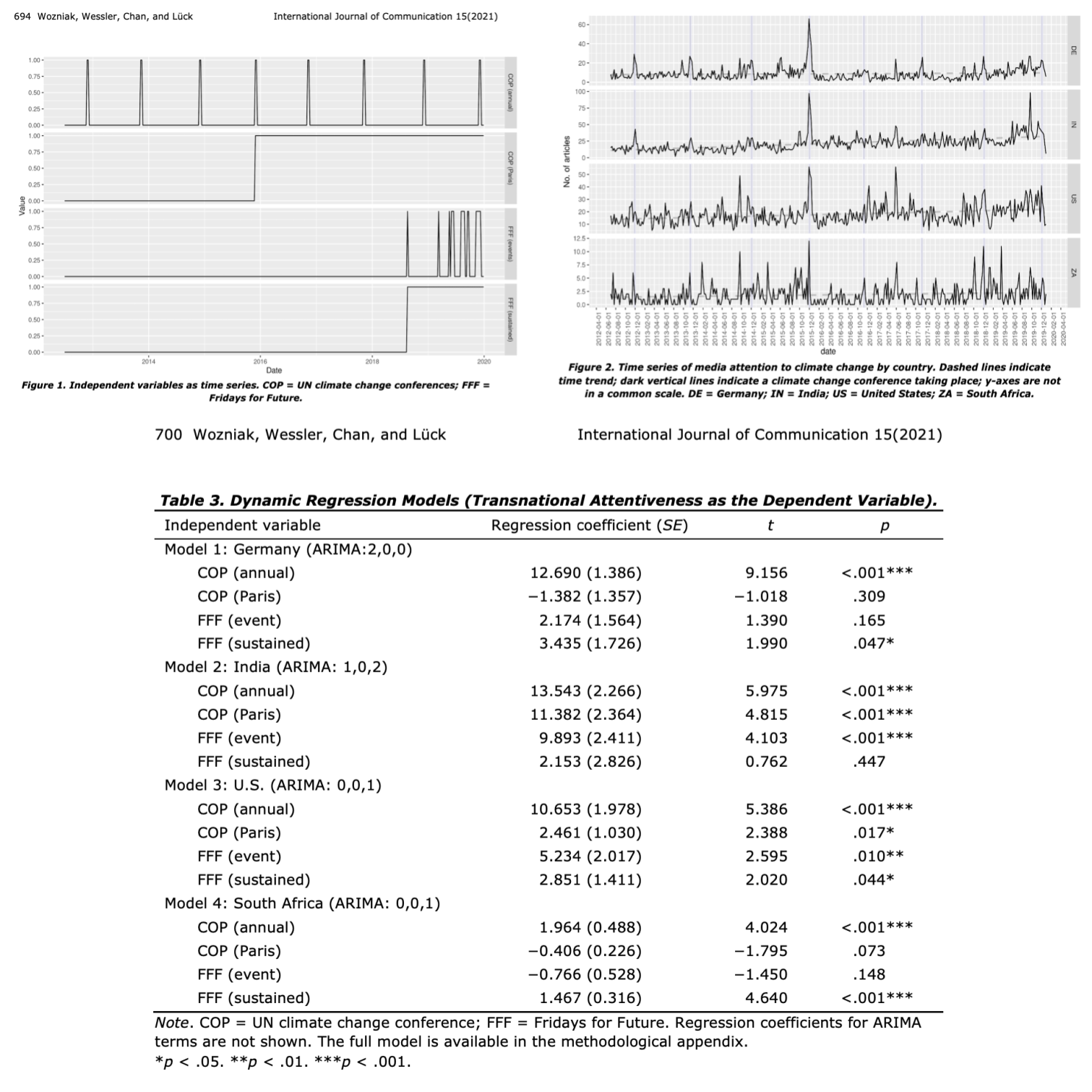
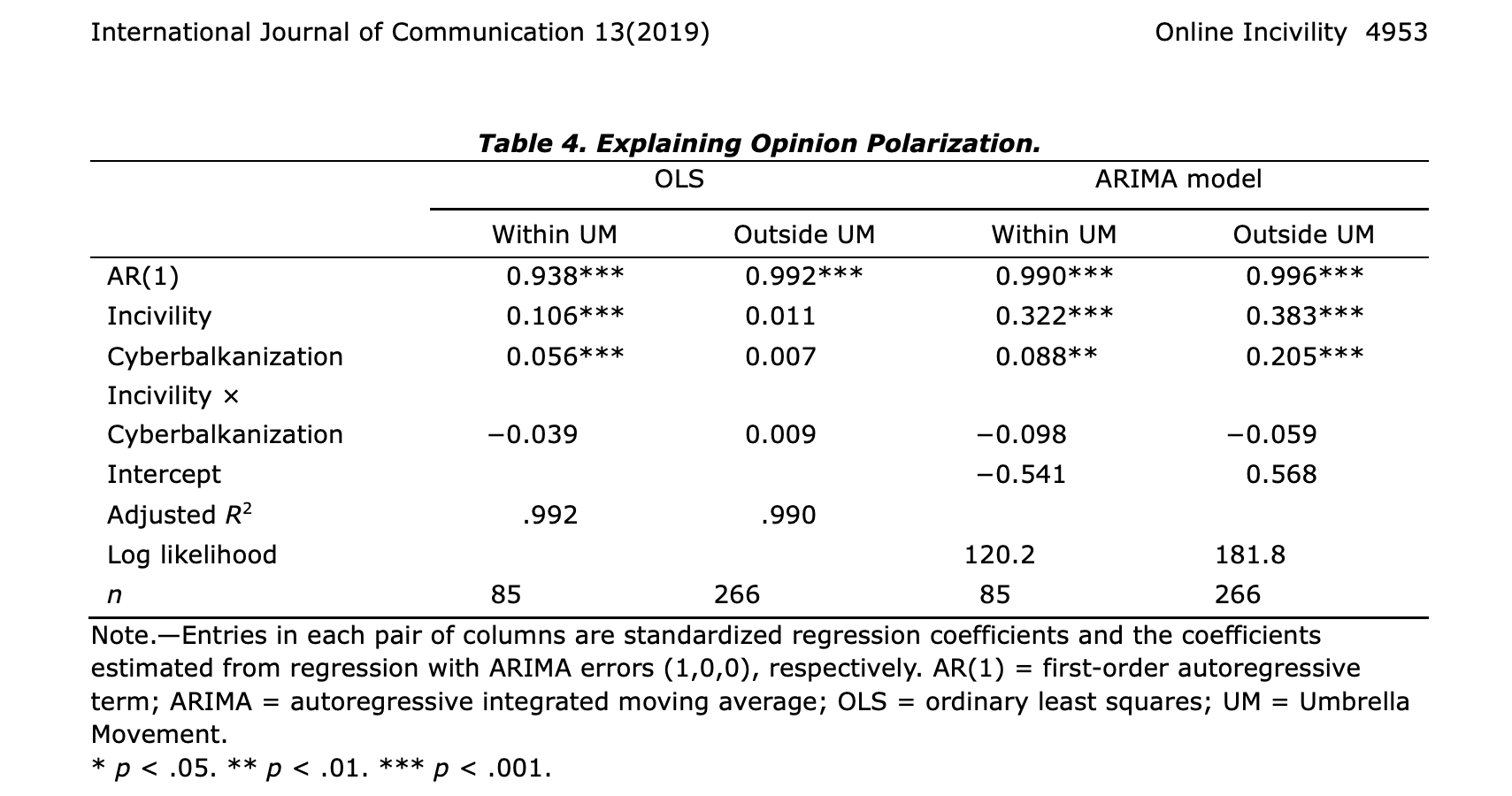
In Online incivility, cyberbalkanization, and the dynamics of opinion polarization during and after a mass protest event5, the authors used both standard regression and regression with ARIMA errors to show that “online incivility — operationalized as the use of foul language — grew as volume of political discussions and levels of cyberbalkanization increased. Incivility led to higher levels of opinion polarization.”. Also in this case the authors analyze a “static process”, that is, focus on contemporary relationships between variables.
In Beyond cognitions: A longitudinal study of online search salience and media coverage of the president6, the authors used regression models with ARIMA errors to examine shifts in newswire coverage and search interest among Internet users in President Obama during the first two years of his administration (2009-2010).
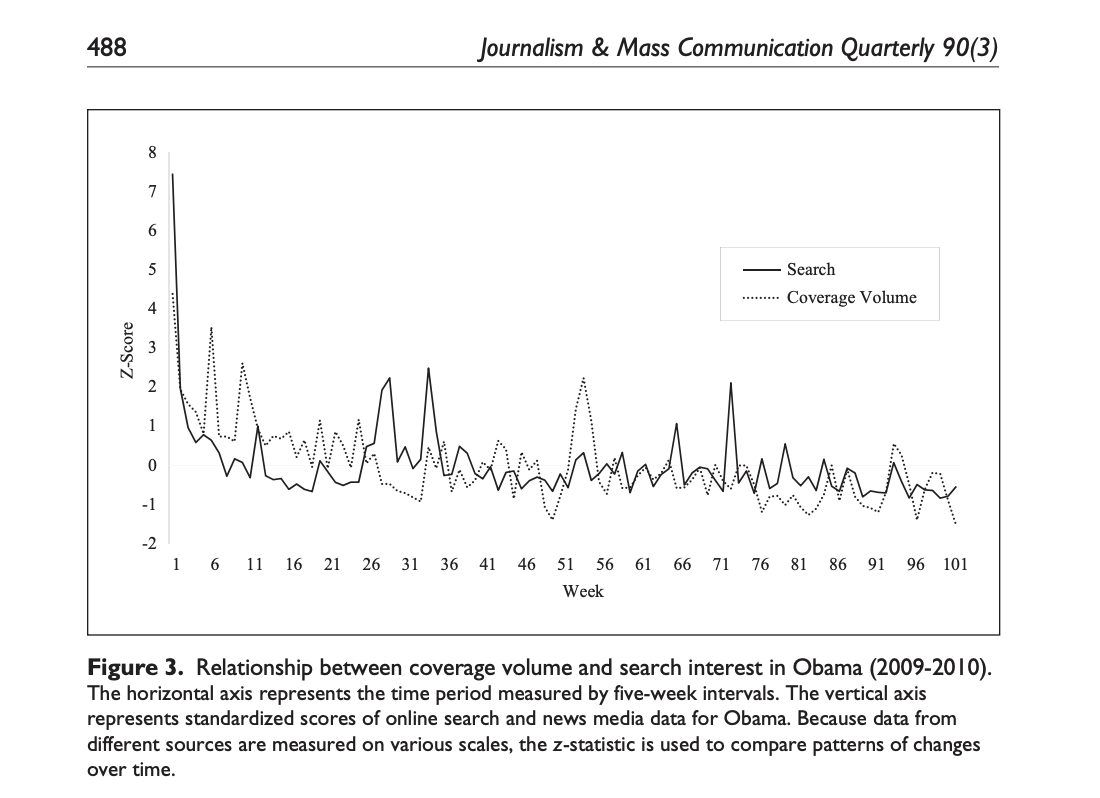
In this case, the authors analyze relationships between variables taking into account lagged values, thus adopting a “dynamic process” perspective. For instance, they write:
RQ2 sought to determine the time span of linkages between coverage volume and search volume. (…) ARIMA models were run to gauge the dynamics of mutual influence between these two time series. The first model examined the effect of coverage volume on search volume over time (i.e., basic agenda setting) (…) presidential public relations, was included as an additional input series. The first model, with search volume being a single dependent variable, was identified through a close examination of autocorrelation functions (ACFs) and partial autocorrelation functions (PACFs). This analysis revealed a classic autoregressive model for the series (1, 0, 0). […] According to the results, shifts in aggregate search volume over this two-year period were significantly predicted by coverage volume over the prior five weeks (p < .010)* and by presidential public relations efforts in the preceding two, three (p < .001), and five weeks (p < .005). The ARIMA model with two predictors was correctly specified (Ljung–Box Q = 18.132, p = .381) and it explained roughly 35% of the observed variation in the series.
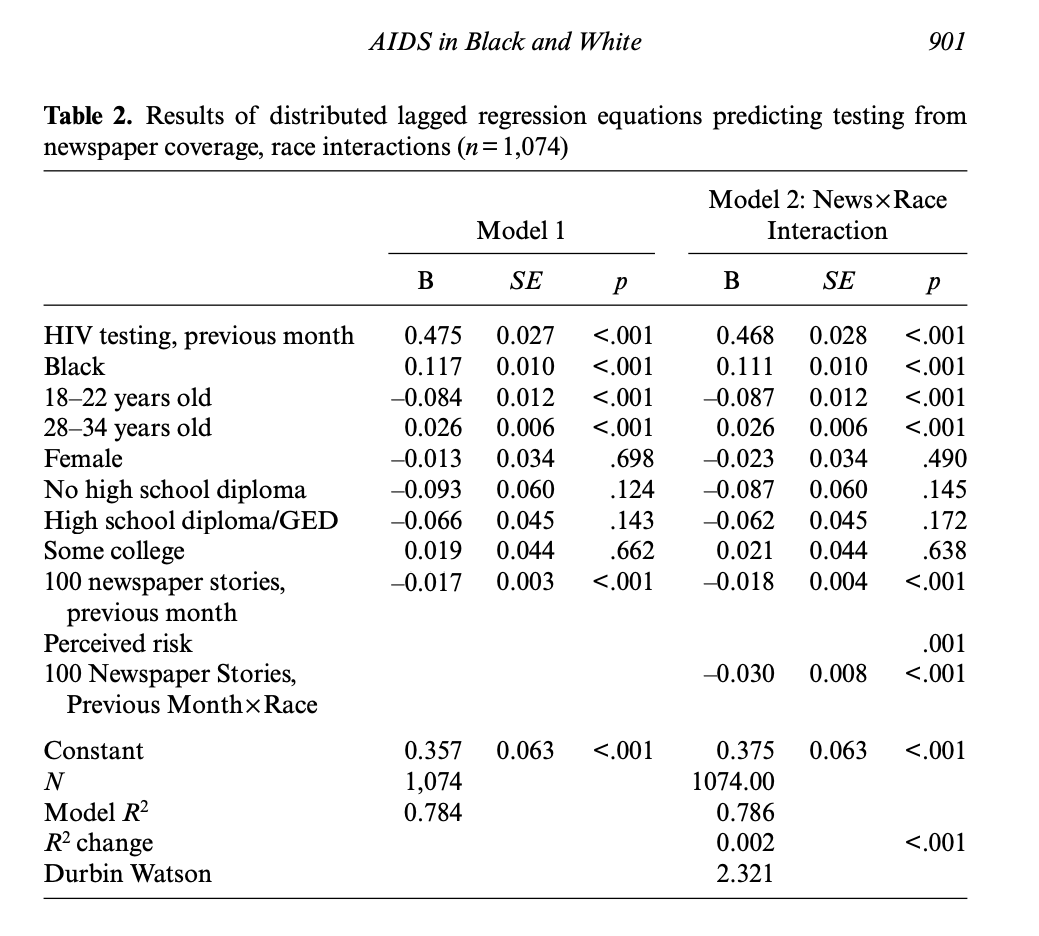
In AIDS in black and white: The influence of newspaper coverage of HIV/AIDS on HIV/AIDS testing among African Americans and White Americans, 1993–20077, the authors examined the effect of newspaper coverage of HIV/AIDS on HIV testing behavior in a U.S. population., using a lagged regression to support causal order claims by ensuring that newspaper coverage precedes the testing behavior with the inclusion of the 1-month lagged newspaper coverage variable in the model. Counterintuitively, they found that the news media coverage had a negative effect on testing behavior: For every additional 100 HIV/AIDS risk related newspaper stories published in this group of U.S. newspapers each month, there was a 1.7% decline in HIV testing levels in the following month, with a higher negative effects on African Americans.